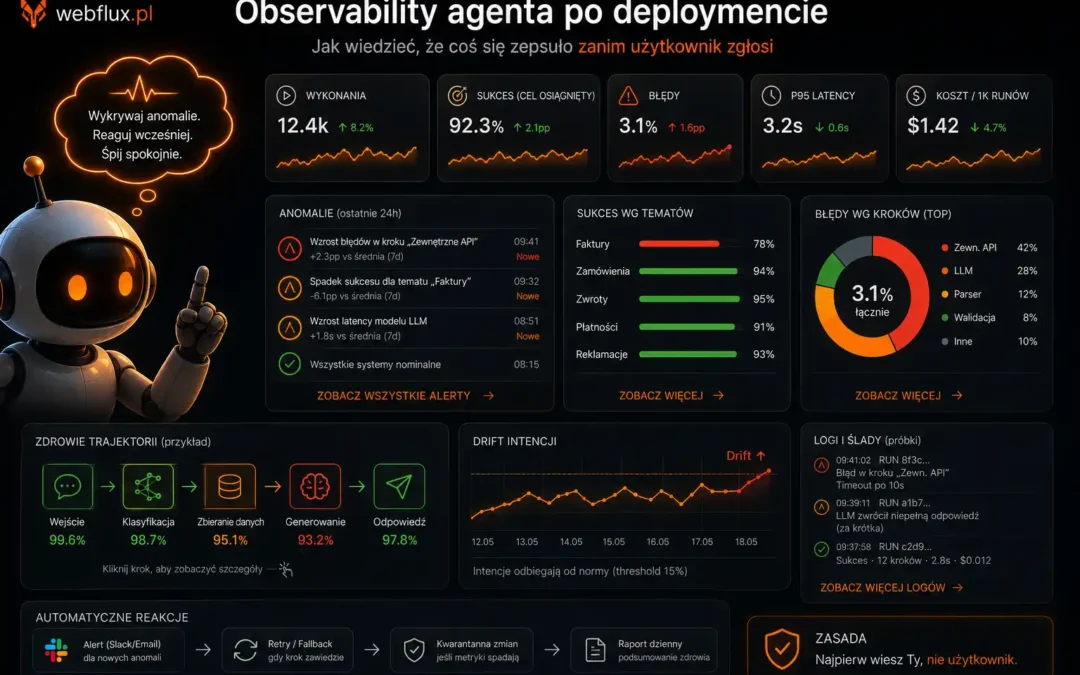
Przeszedł wszystkie testy przed wdrożeniem. Tydzień później provider po cichu zaktualizował model. Nikt Ci o tym nie powiedział. Artykuł 9 serii i dwa poprzednie wpisy tego wątku — ewaluacja trajektorii i ewaluacja w n8n — dotyczyły jednego momentu: przed wdrożeniem....
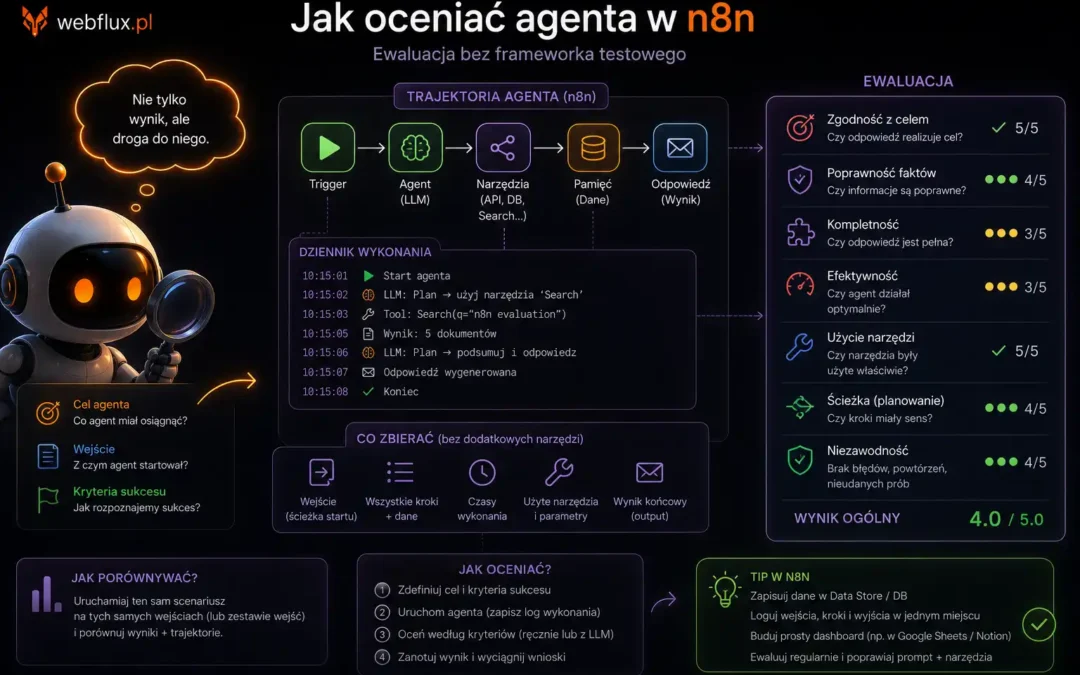
Cały internet o ewaluacji agentów zakłada, że umiesz pisać testy w Pythonie. A Ty zbudowałeś agenta w n8n i nie masz żadnego „evaluate.py”. I to też jest OK. Artykuł 9 serii dał solidne fundamenty ewaluacji — metryki, zestaw testowy, LLM-as-judge, CI/CD. Ale...
Agent dał dobrą odpowiedź. Ale czy doszedł do niej właściwą drogą? Artykuł 9 serii postawił pytanie: czy agent robi to co powinien? I dał narzędzia do mierzenia tego — task completion, tool call accuracy, faithfulness, efficiency. To jest fundament, i jeśli go nie...