Czym jest NLWeb
NLWeb to otwarty standard Microsoftu który pozwala stronie internetowej odpowiadać na pytania w języku naturalnym — zarówno od ludzi jak i od agentów AI.
Bez NLWeb: agent otwiera stronę, scrape’uje HTML, próbuje zrozumieć strukturę, szuka odpowiedzi w treści.
Z NLWeb: agent wysyła pytanie do /ask. Strona odpowiada bezpośrednio.
Microsoft ogłosił NLWeb 19 maja 2025 na konferencji Build 2025, nazywając go „HTML dla agentic web”. Wśród pierwszych partnerów którzy zadeklarowali adopcję: Shopify, TripAdvisor, O’Reilly Media, Snowflake.
Repozytorium: github.com/nlweb-ai/NLWeb
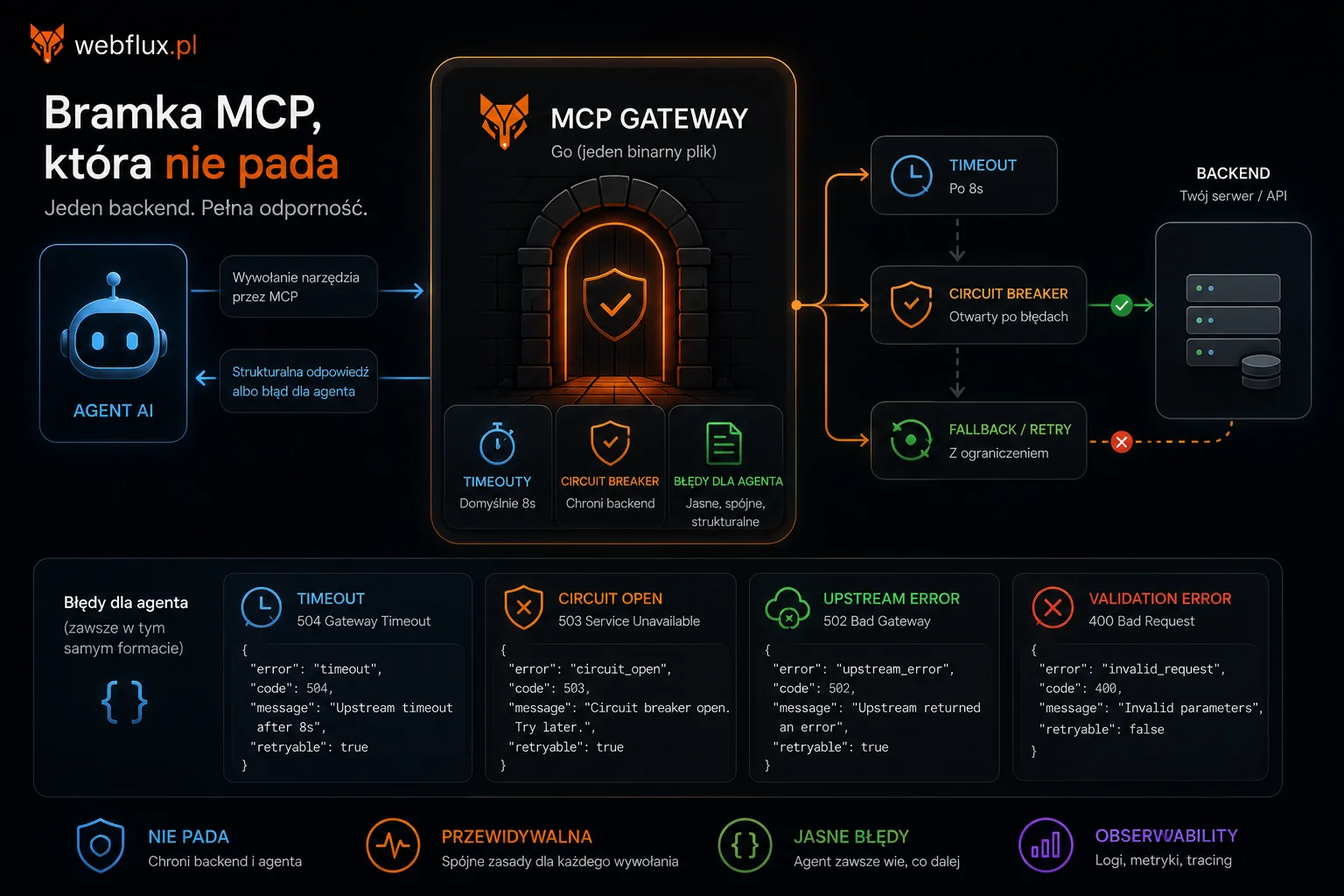
Dwa endpointy
NLWeb definiuje dwa standardowe punkty dostępu:
/ask — konwersacyjny endpoint dla zapytań w języku naturalnym. Użytkownik lub agent pyta: „jakie usługi oferujecie?” Strona odpowiada na podstawie swojej treści. Działa jak chatbot oparty na zawartości witryny — bez konieczności budowania osobnego UI.
/mcp — endpoint MCP dla agentów AI. Zamiast czytać stronę, agent wywołuje funkcję. Ustrukturyzowany dostęp do treści i akcji strony zgodny z Model Context Protocol Anthropic.
Oba endpointy razem sprawiają że strona przestaje być pasywnym dokumentem do odczytania i staje się aktywnym uczestnikiem rozmowy z agentem.
Związek z MCP i WebMCP
NLWeb, MCP i WebMCP rozwiązują ten sam problem w różnych warstwach:
MCP (Anthropic) — protokół komunikacji między modelem AI a narzędziami po stronie serwera.
WebMCP (propozycja Chrome/W3C) — standard przeglądarkowy po stronie klienta. Strona wystawia listę akcji bezpośrednio w przeglądarce.
NLWeb (Microsoft) — protokół dla stron internetowych. Strona wystawia endpoint który rozumie pytania w języku naturalnym. Implementuje /mcp jako jeden z endpointów — jest kompatybilny z ekosystemem MCP.
Trzy standardy, trzy warstwy. Mogą współistnieć na tej samej stronie.
Historia bezpieczeństwa — czego nauczyła pierwsza podatność
Kilka tygodni po ogłoszeniu NLWeb, niezależni badacze bezpieczeństwa Aonan Guan i Lei Wang odkryli w implementacji referencyjnej klasyczny błąd path traversal.
Mechanizm był prosty: przez spreparowany URL można było nawigować poza dozwolone katalogi i odczytać dowolne pliki na serwerze bez uwierzytelnienia. W tym pliki .env z kluczami API do modeli językowych — GPT-4, Gemini i innych.
Guan opisał konsekwencję precyzyjnie: „Te pliki zawierają klucze API dla modeli językowych, które są kognitywnym silnikiem agenta. Atakujący nie kradnie tylko poświadczenia — kradnie zdolność agenta do myślenia, rozumowania i działania.”
1 lipca 2025 Microsoft wydał łatkę. Jednocześnie odmówił przyznania identyfikatora CVE, łamiąc standardowe praktyki odpowiedzialnego ujawniania podatności. Uzasadnienie: kod referencyjny nie jest używany bezpośrednio w produktach Microsoft. Wszystkie wdrożenia oparte na repozytorium pozostawały jednak narażone do czasu aktualizacji.
Szczegóły wyszły publicznie w sierpniu 2025. Instalacje które nie zaktualizowały się po 1 lipca pozostawały narażone przez kolejne tygodnie.
Dlaczego to ważne dla właścicieli stron:
Path traversal to błąd z lat 90. Pojawił się w protokole który miał być „HTML dla agentic web” — w centralnym punkcie który trzyma klucze API do wszystkich zintegrowanych modeli językowych. Ta sama historia co LiteLLM, Flowise, Marimo — stare klasy błędów, nowe miejsce, nowe konsekwencje.
Jeśli wdrażasz NLWeb przez własne repozytorium — sprawdź czy używasz wersji po 1 lipca 2025.
Jak wdrożyć — trzy ścieżki
Ścieżka 1: Cloudflare AI Search (najprostsza) Cloudflare oferuje wdrożenie NLWeb przez dashboard AI Search bez pisania kodu. Crawluje stronę, indeksuje treść, deployuje Worker z endpointami NLWeb. Publiczne preview — kontakt przez nlweb@cloudflare.com dla wdrożeń produkcyjnych.
Ścieżka 2: Implementacja referencyjna Repozytorium GitHub zawiera implementację w Pythonie. Wymaga własnego serwera, obsługuje różne backendy dla wektorowego wyszukiwania (Azure AI Search, Qdrant, Snowflake i inne).
Ścieżka 3: Cloudflare Worker Template Worker z gotową implementacją endpointów NLWeb. Deployujesz na własnym koncie Cloudflare, pełna kontrola nad konfiguracją.
Co NLWeb zmienia dla właścicieli stron
llms.txt i llms-full.txt mówią agentowi co strona zawiera. NLWeb pozwala agentowi wejść w dialog z treścią strony — zadać pytanie i dostać odpowiedź bez scrape’owania HTML.
Dla właścicieli sklepów, firm usługowych i serwisów contentowych — każda strona z NLWeb staje się de facto asystentem AI opartym na własnych danych, dostępnym dla każdego agenta który zna standard.
Dla kogo teraz
Deweloperzy i osoby techniczne — które chcą eksperymentować ze standardem zanim stanie się powszechny. Cloudflare Worker daje działający endpoint w kilka godzin, bez dotykania istniejącej strony.
Właściciele serwisów contentowych — dokumentacja, baza wiedzy, FAQ — to przypadki gdzie /ask ma natychmiastową wartość. Agent który obsługuje klienta nie musi scrape’ować — pyta.
Jeśli potrzebujesz agent-readiness dziś i nie chcesz eksperymentować — zacznij od llms.txt i structured data. Jeśli chcesz być gotowy na to co standardem stanie się za rok — NLWeb jest ważniejszy niż WebMCP bo ma działającą implementację dostępną teraz.