Webflux.pl Agentic Web
Anatomia Agenta AI
Wszyscy mówią o agentach.
Mało kto wie co jest w środku.
Agent AI to nie chatbot z lepszym promptem. To system który planuje, wywołuje narzędzia, ocenia wyniki i wraca do początku — dopóki zadanie nie jest skończone. Różnica jest fundamentalna i nie widać jej z zewnątrz.
Ta seria wchodzi do środka.
Dziesięć artykułów — od mechaniki działania agenta przez pamięć, prompt engineering i pierwsze praktyczne wdrożenie w n8n, aż po koszty produkcyjne, bezpieczeństwo i testowanie. Każdy artykuł jest samodzielny. Razem tworzą pełny obraz.
Seria jest dla tych którzy budują strony, automatyzują procesy i wdrażają AI — i chcą wiedzieć co tak naprawdę dzieje się gdy agent dostaje zadanie i zaczyna działać. Bez skrótów, bez "AI zmienia wszystko", z konkretnymi przykładami i linkami do słownika gdy pojawia się nowe pojęcie.
Jeśli przeczytałeś artykuł o RAG, Agent AI i Agentic RAG — jesteś w dobrym miejscu żeby zacząć od artykułu drugiego. Jeśli nie — zacznij od niego.

Agent AI i skrzynka mailowa — jak bezpiecznie wysyłać wyceny

Observability agenta po deploymencie — jak wiedzieć że coś się zepsuło zanim użytkownik zgłosi
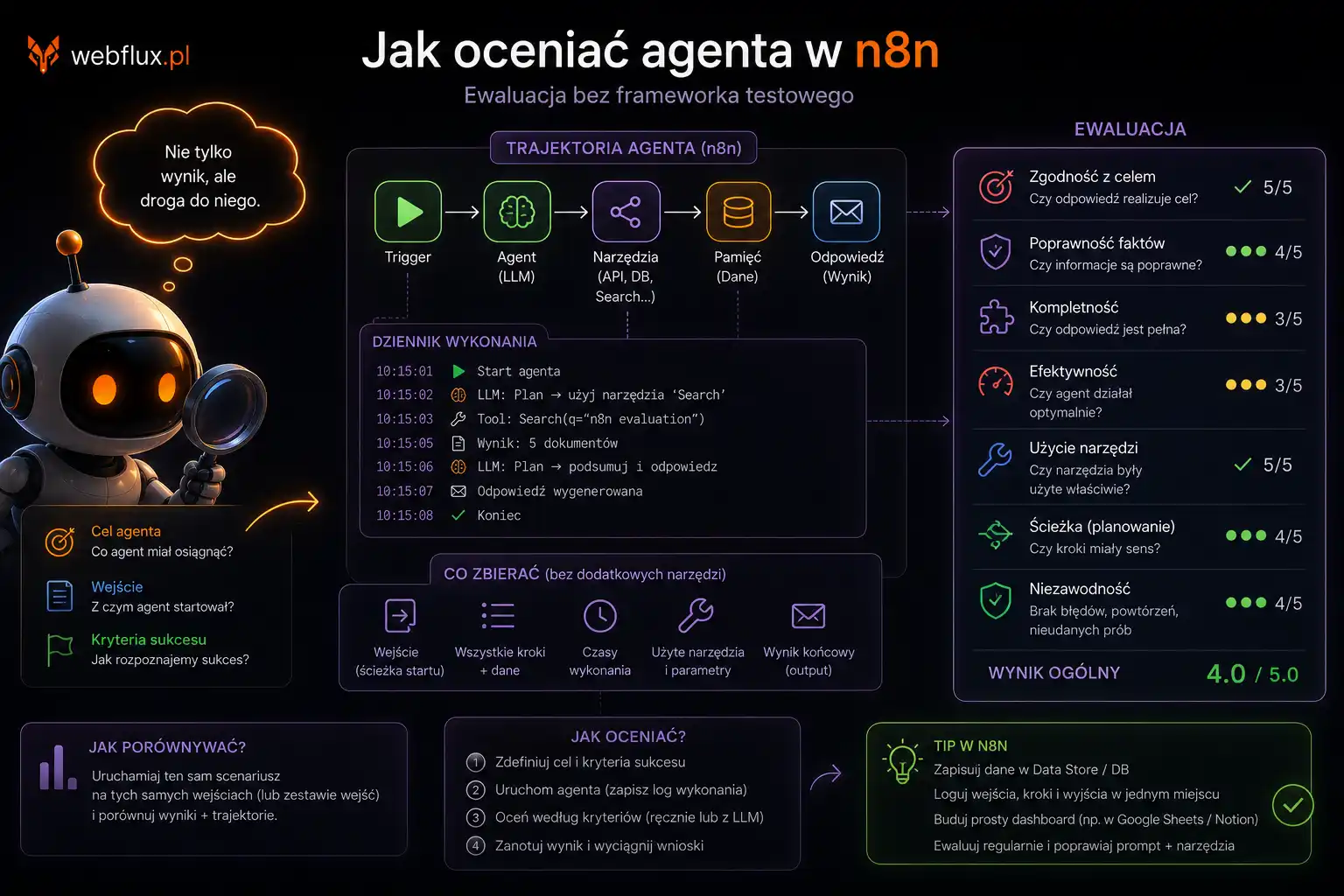
Jak oceniać agenta w n8n — ewaluacja bez frameworka testowego
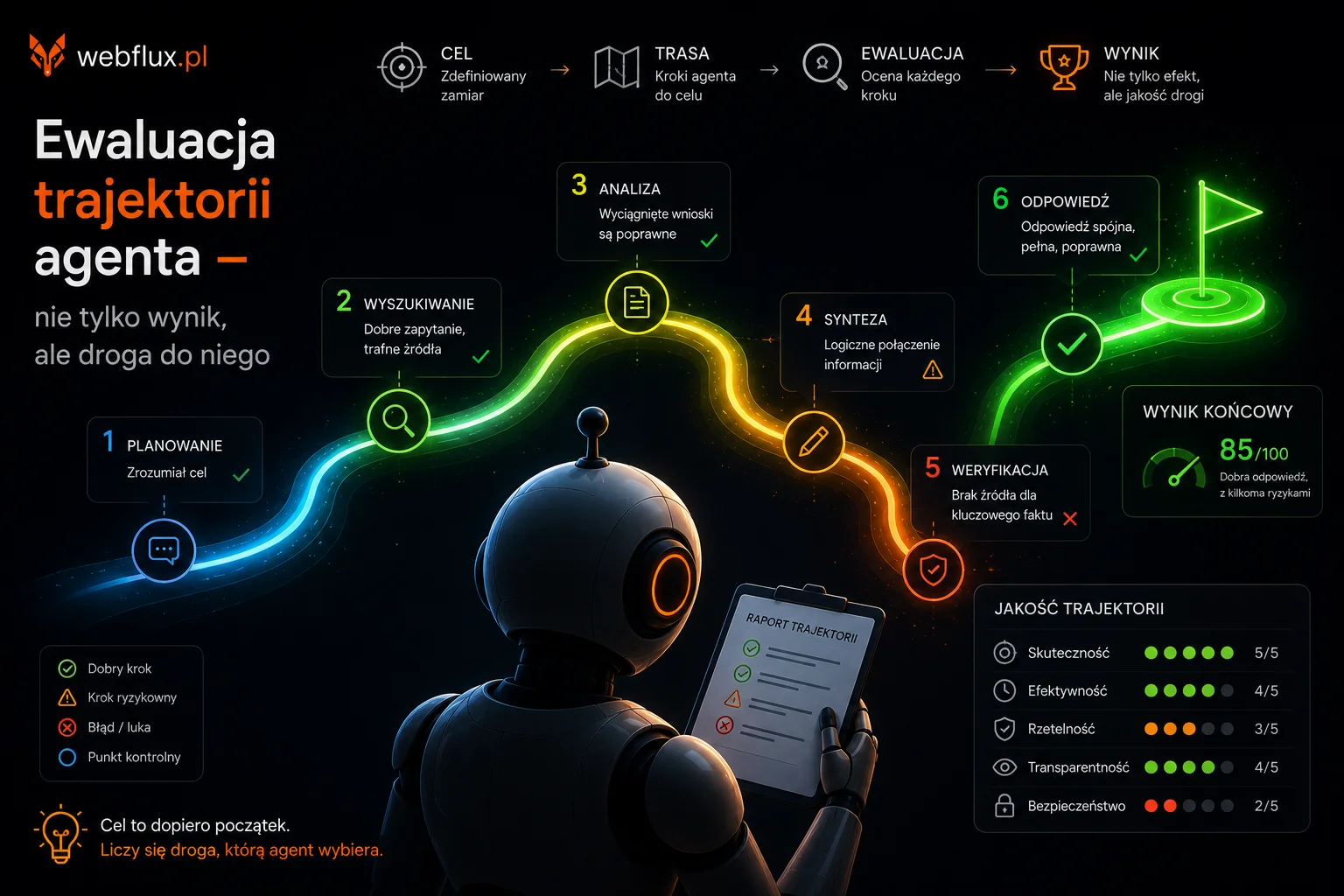
Ewaluacja trajektorii agenta — nie tylko wynik, ale droga do niego

Kiedy nie budować agenta

Agent-ready — checklista na koniec serii i początek wdrożenia

Jak wiedzieć że agent robi to co powinien — ewaluacja, LLM-as-judge i CI/CD

Ile kosztuje agent w produkcji — token cost, model routing i obserwowalność

NLWeb — jak sprawić żeby Twoja strona odpowiadała agentom

Co może pójść nie tak — bezpieczeństwo agentów dla builderów
Context Engineering
Prompt to jedno zdanie. Kontekst to wszystko, co model widzi, zanim odpowie.
Prompt engineering nauczył nas szlifować pytanie. Ale agent nie dostaje pytania — dostaje całe okno: system prompt, pamięć, wyniki narzędzi, pobrane dane, przykłady. To, czy zadziała, rozstrzyga się w tym, co i w jakiej kolejności trafia do okna. To jest context engineering.
Ta sekcja to nie kontynuacja serii o agencie — to jej drugi tor. Seria pokazuje, z czego zbudowany jest agent. Tu pokazujemy, jak składać kontekst, żeby ten agent robił to, co powinien.
Każdy wpis jest samodzielny i linkuje wstecz do odpowiedniego artykułu „Anatomii", gdy dotyka cegły, którą tamta seria już opisała (pamięć, system prompt, RAG, pętla). Jeden organizm, dwa tory.
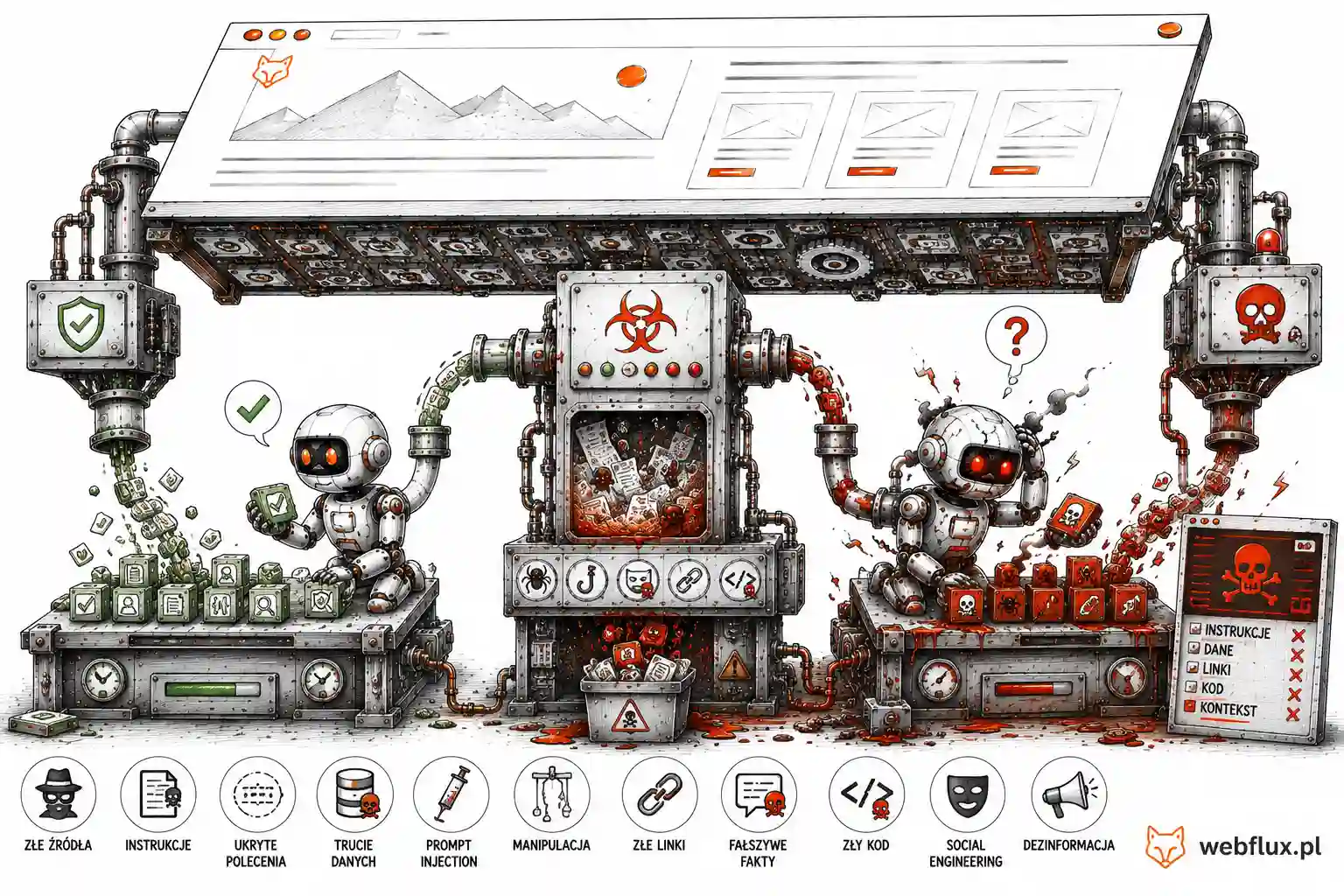
Zatruty kontekst — kiedy to, co wpada do okna, jest atakiem

Formatowanie wyników narzędzi i structured output — kontekst, który agent rozumie

Few-shot w praktyce — jak dobierać przykłady, żeby model robił to, co chcesz

Kompaktowanie kontekstu — jak agent nie gubi wątku przy długich przebiegach

Retrieval jako składanie kontekstu — just-in-time kontra wszystko na raz

Co wrzucić do kontekstu, a co odciąć — anatomia okna agenta

Okno kontekstu, budżet tokenów i context rot — dlaczego więcej nie znaczy lepiej

Context engineering — dlaczego prompt engineering to za mało, kiedy budujesz agenta
Ewaluacja agentów
Zbudować agenta to jedno.
Wiedzieć, że nadal robi to, co powinien - to drugie.
Artykuł 9 serii Anatomia Agenta AI postawił fundament: cztery metryki, zestaw testowy, LLM-as-judge, CI/CD. Ten wątek schodzi głębiej — w trzy miejsca, których jeden artykuł nie obejmie.
Bo ewaluacja agenta to nie jeden test przed wdrożeniem. To trzy różne pytania, zadawane w trzech różnych momentach: czy agent doszedł do wyniku właściwą drogą, jak to sprawdzić bez pisania kodu, i jak nie stracić jakości po wdrożeniu, gdy model pod spodem zmienia się bez Twojej wiedzy.
Każdy wpis jest samodzielny i wraca do art. 9 jako fundamentu. Razem odpowiadają na pytanie, które pojawia się dokładnie wtedy, gdy pierwszy agent trafia do ludzi: skąd właściwie wiem, że to działa — i że nadal działa jutro.
Bez frameworków na siłę, bez „wystarczy go przetestować". Zacznij od dowolnego wpisu poniżej.