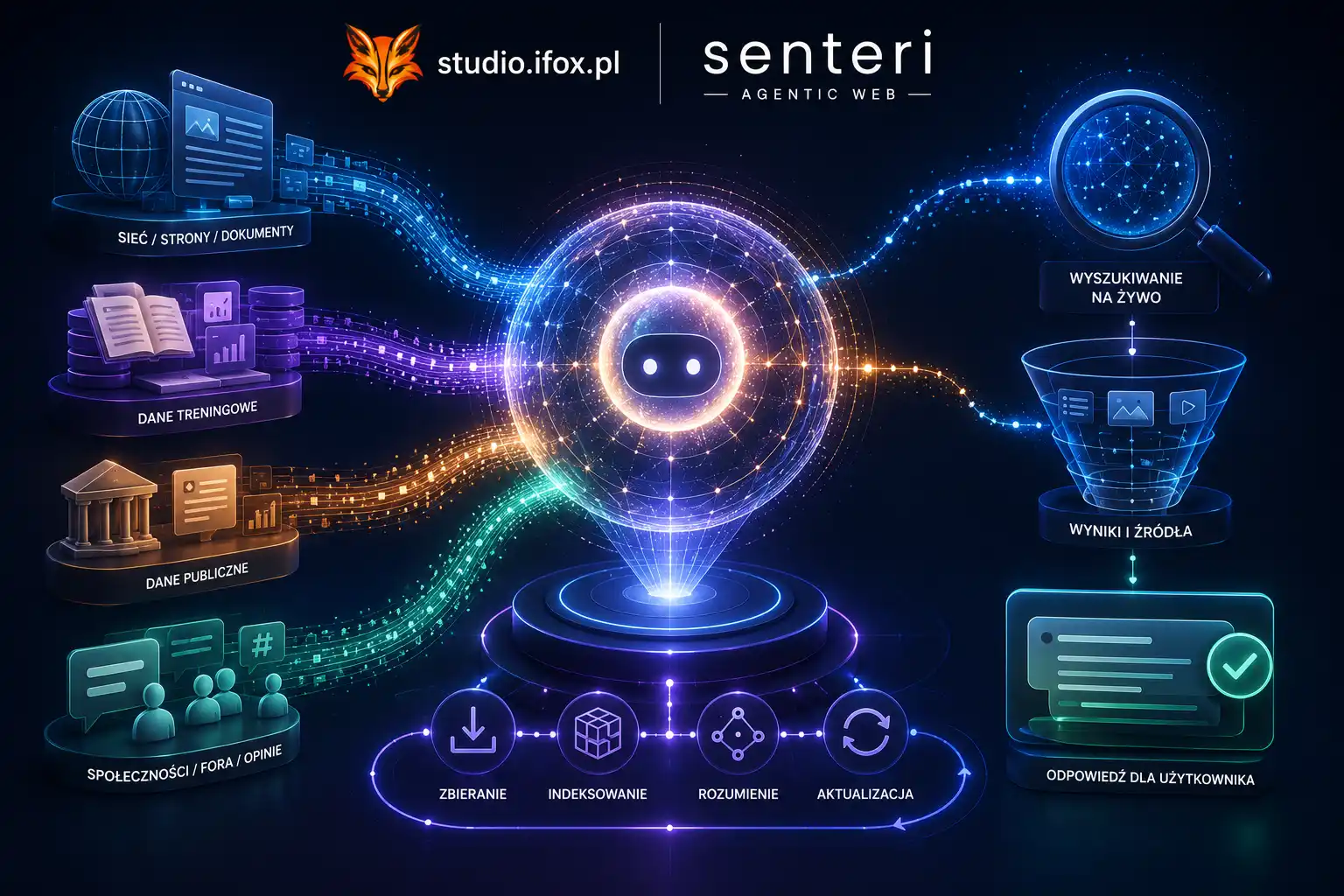
Browser-as-Agent jako pojęcie wprowadziliśmy do słownika webflux.pl jakiś czas temu w 2026. Klaster 14 pojęć wokół niego rozbudował się w kolejnych tygodniach. Wpis „Twoja strona ma od teraz pierwszego czytelnika” z 22 maja opisał paradygmat operacyjny — model AI w przeglądarce użytkownika, który czyta i interpretuje strony przed nim.
Do 19 maja 2026 to było pisanie o paradygmacie. Trochę nadal teoretycznym, choć ewidentnie nadchodzącym. Wystarczająco realnym, żeby uzasadnić budowanie słownika i poradników, jednak nie na tyle codziennym, by oczekiwać od polskich firm zmian w briefach do agencji.
19 maja 2026 paradygmat zmienił status. Google na I/O ogłosił dwa produkty: Auto Browse (agent wykonujący zadania w przeglądarce użytkownika) i Gemini Spark (24/7 personal AI agent monitorujący kontekst użytkownika i podejmujący proaktywne akcje). Razem stanowią pierwszą produktową implementację Browser-as-Agent w mainstreamowej, masowej dystrybucji.
To znaczy że od końca czerwca 2026, kiedy Auto Browse trafi na Androida, twoja strona będzie odwiedzana przez agenta. Nie jako możliwa przyszłość. Jako standardowa kategoria ruchu — jedna z kilku, obok ludzkiego ruchu organicznego, ludzkiego ruchu z reklam, klasycznego SEO crawlera.
Co Auto Browse robi — krótko
Auto Browse to funkcja Gemini in Chrome, zasilana modelem Gemini 3.5 Flash, wykonująca zadania w przeglądarce użytkownika w jego imieniu. Już dostępna na Chrome desktop. Premiera na Android: koniec czerwca 2026.
Typowe zadania, które Auto Browse wykonuje:
- znalezienie parkingu blisko wydarzenia,
- sprawdzenie dostępności produktu w wielu sklepach jednocześnie,
- wypełnienie formularza rezerwacyjnego,
- zakup biletów,
- porównanie cen,
- znalezienie najlepszej oferty pożyczki/ubezpieczenia/usługi,
- assemblowanie listy potencjalnych klientów z LinkedIn / portali branżowych.
Agent działa autonomicznie po wstępnym poleceniu użytkownika. Może otwierać taby, czytać zawartość, wypełniać formularze, klikać przyciski. Czas wykonania typowego zadania: 15-60 sekund.
Z perspektywy strony to wygląda jak normalny user, ale z określonymi charakterystykami: szybsze decyzje, mniej impulsywne zachowanie, większa wrażliwość na strukturę informacyjną. Człowiek scrolluje, ogląda, czyta wybiórczo — agent parsuje zawartość kompleksowo i wybiera deterministycznie.
Co Gemini Spark dodaje — 24/7 personal AI
Gemini Spark to wyższy tier funkcjonalności, dostępny dla subskrybentów Google AI Ultra ($100/m). Spark działa jako persistent AI agent — 24/7 monitorujący kontekst użytkownika (kalendarz, mail, otwarte taby, lokalizację, browsing patterns) i podejmujący proaktywne akcje.
Kluczowe funkcjonalności Spark:
- Daily Brief — codzienne podsumowanie kontekstu (rano, automatycznie),
- Cross-tab actions — agent rozciągający się przez wiele tabów,
- Proactive suggestions — agent sugeruje akcje na podstawie kontekstu,
- Custom agentic workflows — power users definiują własne workflow’y,
- Background tasks — Spark działa w tle.
Różnica między Auto Browse a Spark: Auto Browse jest reaktywne (czeka na polecenie), Spark jest proaktywne (inicjuje sam). To dwa różne paradygmaty interakcji agenta z użytkownikiem.
Razem — emergent zachowania
Auto Browse i Gemini Spark działają najmocniej razem. Spark monitoruje kontekst, decyduje że potrzebna jest akcja, wywołuje Auto Browse który tę akcję wykonuje.
Przykład: 18:00, użytkownik kończy pracę. Spark wie z kalendarza że ma teatr o 20:00 na Mokotowie. Wie z analytics codziennego patternu, że użytkownik zwykle szuka parkingu. Inicjuje suggestion: „Mam ci znaleźć parking blisko teatru?”. Klik akceptacji → Auto Browse robi wyszukiwanie, rezerwację, płatność. 47 sekund.
Drugi przykład, mniej oczywisty. Spark zauważa że użytkownik ma w bookmarkach link do produktu, którego nie kupił (porzucony koszyk z tygodnia temu). Wie z newslettera mailowego, że ten produkt jest teraz na promocji. Proaktywnie inicjuje: „Widzę że oglądałeś X tydzień temu. Jest teraz w promocji o 30%, mam kupić?”.
To zachowanie zmienia fundamentalnie sposób w jaki użytkownik wchodzi w interakcję ze stronami. Klasyczne user journey „świadomość → zainteresowanie → decyzja → zakup” w erze Spark + Auto Browse może być skompresowane w jeden moment akceptacji propozycji agenta. Strona widzi tylko ten ostatni moment.
Co strona musi mieć, żeby Auto Browse mógł skutecznie działać
Strony różnie radzą sobie z agentem. Niektóre — agent kończy zadanie w 30 sekund. Inne — agent się gubi, próbuje, fail’uje, rezygnuje. W obu przypadkach to ta sama strona, ale agent nie wykonał zadania.
Co decyduje:
Hierarchia semantyczna HTML. Agent parsuje DOM i buduje mapę informacyjną strony. Strona z poprawnym <article>, <nav>, <main>, <section>, <aside>, <footer> daje agentowi natychmiastową orientację. Strona z <div class="container">zagnieżdżonym 12 razy wymaga od agenta wnioskowania struktury z visual cues — czego agent nie ma.
Formularze z odpowiednim labelowaniem. Każdy input powinien mieć <label> powiązany przez for/id lub aria-label. Placeholder text nie wystarcza — agent czyta najpierw <label>, dopiero potem placeholder. Brak label = agent zgaduje co pole znaczy.
Schema.org dla danych strukturyzowanych. Strony e-commerce z Product schema, strony booking z Service / Event schema, strony oferujące oferty z Offer schema. Agent wykonujący zadanie „znajdź najtańszy parking na 4h” potrzebuje cen w strukturze, nie w plain texcie „od 5 zł / h”.
Stan koszyka / sesji odpowiednio reflektowany w UI. Agent dodaje produkt do koszyka. Strona aktualizuje UI („Dodano do koszyka”), ale nie aktualizuje semantyki (live region, aria-live, semantic feedback). Agent nie wie czy operacja się powiodła — czeka, traci czas, może w końcu spróbować ponownie i dodać dwa razy.
Brak skomplikowanych modali i wieloetapowych wizardów bez clear progress. Agent może nie rozpoznać że jest w środku 5-krokowego procesu. Wizardy powinny być semantycznie oznaczone (step indicator z aria-current=”step”), z możliwością nawigacji wstecz.
Brak CAPTCHA na typowych akcjach (poza krytycznymi). CAPTCHA jest jak bariera dla agenta — dla niego nieprzepuszczalna (większość). Strona z CAPTCHA na każdym formularzu odsuwa cały ruch agentowy. Strona z CAPTCHA tylko na „krytycznych” akcjach (płatność powyżej X, transfer pieniędzy) daje agentowi możliwość wykonania reszty zadania.
llms.txt z opisem strony. Plik llms.txt w root domeny opisujący semantykę i strukturę strony dla LLM-ów / agentów. Względnie nowa konwencja (proponowana w 2024), Google teraz oficjalnie ją wspiera dla Auto Browse.
UX/IA zmiany — pięć konkretnych przesunięć
Praktyka projektowania interface’ów się zmienia. Pięć konkretnych zmian, które zauważam w briefach do agencji projektowych w pierwszej połowie 2026:
Zmiana 1: hierarchia informacyjna agresywnie spłaszczana
Strony z głębokimi hierarchiami (menu główne → kategoria → podkategoria → produkt) były projektowane dla człowieka, który nawigowuje wzrokiem. Agent woli płaską hierarchię gdzie pełna ścieżka do dowolnego produktu/usługi nie wymaga więcej niż 2 kliknięć.
Praktyczna implementacja: search jako primary navigation, nie secondary. Filtry semantyczne (cena, kategoria, lokalizacja) jako structured query params w URL. URL-e zawierające informację o stanie strony (nie hash routing).
Zmiana 2: formularze multi-step → formularze single-step z conditional logic
Klasyczne wieloetapowe formularze (5-7 kroków) były projektowane dla człowieka który chciał mieć małe psychiczne dawki informacji. Agent woli single-page formularze gdzie widzi wszystkie wymagane pola jednocześnie.
Praktyczna implementacja: jeden formularz z dynamicznie pokazywanymi sekcjami w zależności od wyborów. Conditional logic on client side. Wszystkie pola w jednym DOM, część visible, część collapsed.
Zmiana 3: confirmation patterns – explicit dla krytycznych akcji
Skoro agent może wykonać wiele akcji w sekwencji, krytyczne kroki potrzebują explicit confirmation patterns które wymagają interakcji wykraczającej poza scope agenta.
Praktyczna implementacja: dla płatności powyżej X — 2FA przez SMS/TOTP. Dla zmian konta — email confirmation z magic link (agent nie czyta maila per default). Dla transferów pieniędzy — hardware key.
Tu pojawia się tension z UX dla człowieka — confirmation patterns są friction. Rozwiązanie: differential friction. Małe transakcje (zakup parkingu za 15 zł) → frictionless. Duże (zakup laptopa za 5000 zł) → confirmation. Threshold customizable per user.
Zmiana 4: feedback states – audible/semantic, nie tylko visual
Klasyczne feedback states („Dodano do koszyka” w toast notification) są visual. Agent może nie zauważyć toast’a jeśli zniknie szybko. Lepsze: aria-live regions, semantic state changes, structured success/error responses.
Praktyczna implementacja: każde action ma odpowiadające aria-live announcement. Każdy success/error ma czytelną semantyczną reprezentację (nie tylko visual icon).
Zmiana 5: progressive disclosure → upfront information
Klasyczna zasada UX „progressive disclosure” (pokazuj informacje gdy są potrzebne) była projektowana dla człowieka który ma ograniczoną cognitive bandwidth. Agent ma większą bandwidth — woli mieć wszystkie informacje upfront.
Praktyczna implementacja: pełne specyfikacje produktów na karcie produktowej, nie ukryte za „rozwiń więcej”. Pełne ceny z wszystkimi opłatami widoczne od razu, nie odkrywane na ostatnim kroku checkout’u. Pełne warunki rezerwacji obok formularza, nie w PDF do pobrania.
Konkretne implikacje per typ strony
E-commerce. Agent porównuje produkty między sklepami. Strona z dobrą Product schema (cena, dostępność, parametry, recenzje) wygrywa nad stroną z lepszym designem ale słabszą strukturą danych. Top e-commerce w Polsce (Allegro, Empik, Media Markt) zaczynają agresywnie poprawiać Product schema — to widoczne w changelog Schema.org markup ich stron w maju 2026.
Praktyczna akcja: audyt Product schema z Google Rich Results Test. Pokrycie 100% dla głównych kategorii. Variant schema dla różnych wersji (rozmiar, kolor). Stock availability w realtime.
Strony booking i rezerwacji. Agent szuka tygodniowo: parking, hotel, restauracja, lekarz, dentysta, transport. Każda kategoria ma własną Schema.org reprezentację (LodgingReservation, FoodService, MedicalBusiness). Strona z brakami w schema = agent jej nie znajduje.
Praktyczna akcja: pełna Schema.org implementation dla typu biznesu. Open hours, location, services, pricing — wszystko strukturyzowane. Plus bezpośrednia integracja z Auto Browse-friendly booking flow (jeden formularz, nie wizard).
SaaS i strony usługowe. Agent szuka dostawców usług na podstawie zapytania użytkownika („znajdź mi narzędzie do project management w cenie pod 10 USD/m”). Strona z jasną strukturą cennika, jasnym opisem features, schemami dla różnych planów subskrypcji wygrywa.
Praktyczna akcja: cennik jako structured data (Product / SoftwareApplication schema z Offer). Comparison tables z semantic markup. FAQPage schema dla typowych pytań. Demo/trial dostępne z minimal friction (no credit card upfront).
Strony content (blogi, magazyny, portale). Agent cytuje treści w odpowiedzi na zapytania użytkownika. Strona z dobrą Article schema, jasnym autorstwem, datami publikacji, transcripts dla wideo wygrywa w citation share. To temat pokrywany szczegółowo w klastrze „Mierzenie widoczności AI” w słowniku.
Praktyczna akcja: jak we wpisie ContentFox AI-Readiness Scanner — sześć warstw audytu, plus dochodzą wymiary multi-modal po Gemini Omni (jak we wpisie warstwy 1 huba I/O 2026).
Komplementarność z CyberFlux
Ten wpis koncentruje się na jak zrobić stronę gotową dla Auto Browse. Z perspektywy webmastera, designera, agencji — co projektować, jakie elementy zawrzeć, jakie zmiany w UX wprowadzić.
Flagowy wpis CyberFlux huba I/O 2026 koncentruje się na co zagraża kiedy Auto Browse działa na koncie użytkownika. Threat model, polityki blokady, analiza prawna RODO i ePrivacy.
Te dwa wpisy są komplementarne. Jeden mówi „zrób stronę przyjazną agentowi”, drugi mówi „uważaj na zagrożenia gdy agent ma dostęp do twojego konta”. Oba są prawdziwe równocześnie i obie perspektywy są potrzebne.
Webmaster powinien przeczytać oba. Mając stronę przyjazną agentowi, robisz przysługę użytkownikowi (krótsze zadania, lepsze doświadczenia). Mając świadomość zagrożeń, projektujesz odpowiednie confirmation patterns na critical actions — co chroni jego konto.
Refleksja końcowa
Browser-as-Agent jako paradygmat istnieje od kilku lat. Auto Browse i Gemini Spark są pierwszymi mainstreamowymi produktami, które wnoszą ten paradygmat do codziennej praktyki użytkowników Chrome.
Kiedy paradygmat staje się produktem, zmienia się również perspektywa webmastera. Z „interesujące, może kiedyś” na „musimy zaprojektować odpowiedź teraz, bo ruch agentowy zaczyna być standardową kategorią ruchu”.
Pytanie nie brzmi już „czy zaadaptujemy stronę pod agentów”. Brzmi „kiedy” i „jak szybko zrobimy to lepiej niż konkurencja”. Strony, które się dopasują w drugiej połowie 2026, będą miały istotną przewagę nad konkurencją w 2027-2028. Strony, które zwlekają — będą traciły ruch agentowy w sposób niewidoczny dla nich (Google Search Console nie pokazuje „ile razy Auto Browse pominął moją stronę na rzecz konkurenta”).
Następny wpis w hubie Google I/O 2026 z perspektywy WebFlux: warstwa 4, Intelligent Eyewear — strona internetowa widziana przez okulary.
Powiązane wpisy
W hubie Google I/O 2026:
- Google I/O 2026 — kiedy Agentic Web stała się oficjalną strategią Google (wpis flagowy huba)
- Gemini Omni — kiedy Pierwszy Czytelnik staje się multimodalny (warstwa 1)
- Antigravity 2.0 — kiedy agent-first development przestaje być pluginem do edytora (warstwa 2)
Komplementarny CyberFlux:
- 47 sekund, 3 zakupione produkty, 2 utworzone konta, 0 kliknięć użytkownika (flagowy CyberFlux huba)
Poza hubem:
- Twoja strona ma od teraz pierwszego czytelnika i nie jest nim człowiek
- Przeglądarki AI w 2026 — przegląd
- 10 rzeczy, które agent AI potrafi zrobić na stronie WWW
Słownik: