W listopadzie 2025 pisałem na WebFlux o Atlasie od OpenAI — przeglądarce, która miała być agentem. Tekst kończył się pytaniem: czy web design ma jeszcze sens, jeśli twoja strona jest oglądana przez model AI, nie przez człowieka? Pół roku później wiemy więcej. Atlas się zmaterializował. Claude in Chrome robi co się da. Przeglądarki AI przestały być eksperymentem.
Ale to wszystko były rzeczy, których trzeba było chcieć. Atlas trzeba pobrać. Claude in Chrome trzeba zainstalować. Brave Leo trzeba przełączyć. To są agenty, których użytkownik świadomie wybiera.
Dwa tygodnie temu okazało się, że Google poszedł inną drogą. Bez ogłoszenia, bez UI, bez kliknięcia — Chrome od miesięcy pobiera ~4 GB modelu Gemini Nano na urządzenia użytkowników, którzy spełniają wymagania sprzętowe. Plik nazywa się weights.bin. Leży w katalogu profilu Chrome. Jeśli go usuniesz, wraca w ciągu kilku godzin. Pełną analizę techniczną i prawną — z dokumentacją z poziomu kernela macOS — opisaliśmy szczegółowo na CyberFlux.
Ten tekst nie jest o tym. Ten tekst jest o tym, co to zmienia w tym, co robisz ze swoją stroną.
Krótka odpowiedź: zmienia kogo nazywasz „użytkownikiem swojej strony”. Długa odpowiedź — niżej.
Przeglądarka przestała być pasywna
Przez trzydzieści lat istnienia webu obowiązywała prosta umowa: serwer wysyła HTML, przeglądarka go renderuje. Co użytkownik zobaczył, było dokładnie tym, co autor strony chciał, żeby zobaczył — z niewielkimi modyfikacjami przez CSS użytkownika, dark mode i extension’y, które użytkownik świadomie zainstalował.
Ta umowa zaczęła się rozszczepiać dwa lata temu. Najpierw Edge dodał Copilot na pasku — ale jako wyraźnie oznaczoną funkcję boczną. Potem Brave wprowadził Leo — opt-in, z własnym przyciskiem. Potem Atlas, Arc Max, Vivaldi z lokalnymi modelami tłumaczeń. Każdy z nich był wyraźny: tutaj jest AI, jak chcesz to użyj.
Chrome z Gemini Nano przekroczył próg, którego inni nie. Lokalny LLM jest tam domyślnie. Pobiera się sam. Pracuje w tle. Użytkownik nie wie, że go ma. A funkcje, które ten model napędza — Help me write, smart paste, podsumowywanie strony, sugestie grup kart — działają na zawartości stron, które użytkownik odwiedza. Czyli twojej.
To nie jest mała zmiana. To jest fundamentalna zmiana w kontrakcie strona ↔ klient.
Trzy rzeczy, które Nano robi z twoją stroną — już teraz, na 500 milionach urządzeń
1. Podsumowuje ją zanim użytkownik ją przeczyta. W Chrome 147 funkcja „Summarize this page” jest jednym kliknięciem prawym przyciskiem (a w kanałach beta — jednym przyciskiem na pasku narzędzi). Nano czyta cały DOM, ekstrahuje to, co uważa za istotne, i serwuje 5–7 zdań, które według niego oddają sens twojej strony. Użytkownik przeczyta to podsumowanie zamiast twojego nagłówka. To podsumowanie staje się w jego głowie „twoją stroną”.
2. Parafrazuje ją, gdy użytkownik coś pisze w formularzu na twojej stronie. Help me write działa kontekstowo. Kiedy użytkownik wypełnia formularz kontaktowy na twojej stronie i klika „pomóż mi napisać”, Nano czyta kontekst strony — twoje nagłówki, opis usługi, FAQ — i generuje treść, którą użytkownik wyśle do ciebie. Ta treść jest zinterpretowana przez Nano przez pryzmat tego, co Nano zrozumiał z twojej strony. Twoja oferta, twoje przesłanie, twój język — wszystko zostaje przepuszczone przez filtr modelu, zanim trafi z powrotem do ciebie jako wiadomość od klienta.
3. Grupuje twoje strony razem z innymi w mentalne kategorie użytkownika. Tab group suggestions używają Nano do nazywania i grupowania otwartych kart. Jeśli użytkownik ma otwarte twoją stronę usług kosmetycznych razem z trzema innymi, Nano przeczyta wszystkie cztery i zaproponuje nazwę grupy. Twoja marka znika w generycznym „Salony kosmetyczne — Warszawa”. Konkurencja, która zoptymalizowała stronę pod model, dostanie w tej grupie pierwszą pozycję mentalną; ty będziesz „jeszcze jedną z czterech”.
Każda z tych trzech rzeczy działa bez intencji użytkownika dotyczącej AI. To nie jest „użytkownik włącza Claude’a, żeby ten coś dla niego zrobił”. To jest „użytkownik otwiera Chrome, Nano już tam jest, model decyduje, co użytkownik widzi z twojej strony”.
Browser-as-Agent vs. Agent-in-Browser
To dwa różne paradygmaty i Agentic Web musi je odróżniać.
Agent-in-Browser to było to, co opisywaliśmy w eksperymencie z Claude in Chrome. Użytkownik świadomie odpala Claude’a, każe mu otworzyć stronę kosmetyczki, agent wykonuje zadanie, wraca z odpowiedzią. Agent jest gościem na twojej stronie — wchodzi, robi swoje, wychodzi. Twoja strona może być pod niego zoptymalizowana (agent-readiness), ale agent przyszedł na konkretne zlecenie i odejdzie.
Browser-as-Agent to nowy paradygmat, który właśnie dostarczył Google. Tu agent jest przeglądarką. Nie wchodzi, bo nigdy nie wyszedł. Jest cały czas obecny, czyta każdą twoją stronę, którą użytkownik otwiera, i moduluje doświadczenie strony — czasem widocznie (podsumowanie), częściej niewidocznie (kontekst dla innych funkcji AI, parafraza, klasyfikacja). Twoja strona nigdy nie jest sama z użytkownikiem. Jest zawsze w trójkącie: serwer, Nano, użytkownik.
Te dwa paradygmaty wymagają różnych odpowiedzi od strony.
Pod Agent-in-Browser optymalizujesz na zadanie agenta. Robisz strukturalne dane, czyste semantyczne nagłówki, schema.org, llms.txt — żeby agent, kiedy przyjdzie, mógł wykonać swoje zadanie poprawnie. Sukces mierzysz w „czy agent wykonał akcję, której się od niego oczekiwano”.
Pod Browser-as-Agent optymalizujesz na reprezentację. Robisz strukturalne dane, czyste semantyczne nagłówki, schema.org, llms.txt — i sprawdzasz, czy Nano potrafi z tego zbudować akceptowalne podsumowanie twojej strony. Sukces mierzysz w „czy generowane podsumowanie nie krzywdzi mojej marki”.
Dobra wiadomość: techniczna baza jest ta sama. Strona, która jest agent-ready dla Claude in Chrome, jest też lepiej reprezentowana przez Nano. Zła wiadomość: kryterium sukcesu jest inne, więc testowanie wymaga innych narzędzi.
Pierwszy czytelnik nie jest człowiekiem
To jest sedno tego, co się zmieniło.
Do tej pory, kiedy projektowałeś stronę, twoim pierwszym czytelnikiem był człowiek. Algorytm Google był drugim — i ten algorytm decydował, czy człowiek w ogóle dotrze. Optymalizowałeś dla obu, ale człowiek był celem, a algorytm — kanałem dostarczenia.
W ekosystemie z Gemini Nano w domyślnym Chrome pierwszym czytelnikiem twojej strony staje się model. Nie metaforycznie, dosłownie. Nano czyta DOM zanim użytkownik zacznie scrollować. Jeśli użytkownik kliknie „podsumuj”, to Nano już dawno przeczytał — wystarczy mu sklecić odpowiedź. Jeśli użytkownik użyje „Help me write”, Nano już ma kontekst twojej strony w buforze.
Twój pierwszy czytelnik nie ma oczu. Nie ocenia kolorów, nie ocenia hierarchii wizualnej, nie ocenia mikrointerakcji. Czyta tekst, czyta strukturę, czyta semantykę. Wszystko inne — całe twoje fancy CSS, wszystkie animacje, cały design — istnieje dla użytkownika, który zostaje już zaopiniowany przez model zanim do niego dotrze.
To nie jest wezwanie do porzucenia design’u. To jest wezwanie do zrozumienia, że design rozdziela się teraz na dwie warstwy:
- warstwa dla człowieka — kolor, hierarchia wizualna, mikrointerakcje, marka
- warstwa dla pierwszego czytelnika — semantyka HTML, schema.org, llms.txt, struktura nagłówków, jasność treści tekstowej
Pierwsza warstwa wpływa na to, czy człowiek zostanie. Druga warstwa wpływa na to, jakiego człowieka twoja strona w ogóle dostanie — bo Nano podsumuje, sklasyfikuje, opisze. Człowiek, którego dostajesz na stronie, jest już człowiekiem, który przeczytał wersję Nano twojej strony, nie twoją.
AI Visibility nie jest już dodatkiem do SEO. Jest jego nową warstwą
Klasyczny model widoczności miał dwie warstwy:
- SEO — żeby Google znalazł i zaindeksował,
- UX/copy — żeby człowiek po wejściu został.
Teraz dochodzi warstwa pośrednia:
- AI Visibility — żeby model w przeglądarce (i model w wynikach wyszukiwania) zrozumiał stronę poprawnie i opisał ją tak, jak ty byś chciał.
Tę warstwę ignoruje się na własne ryzyko. Bo jeśli Nano podsumuje twoją stronę usług dentystycznych jako „strona dentysty w Warszawie z cennikiem”, a konkurencyjną — która dała się Nano przeczytać lepiej — jako „centrum stomatologii estetycznej z 15-letnim doświadczeniem, specjalizacja: licówki, implanty, ekspresowe znieczulenie”, to użytkownik, który czytał oba podsumowania zanim wszedł na obie strony, już wybrał konkurencję, zanim zobaczył wasze strony własnymi oczami.
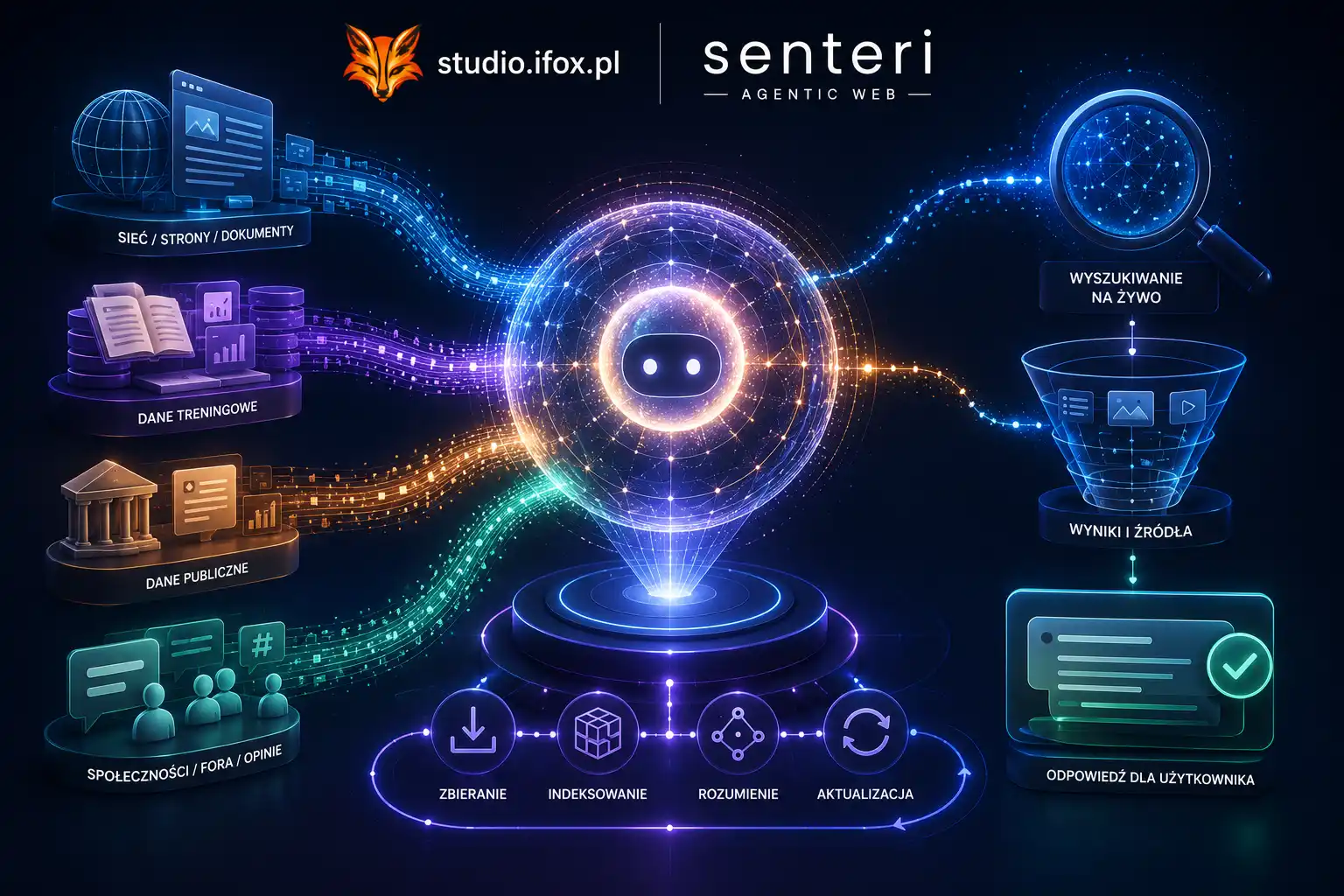
To, co Nano zrobi z twoją stroną, zależy od trzech rzeczy, dokładnie tych samych, które definiują agent-readiness:
Semantyka HTML. <article>, <section>, <nav>, <aside>, <header>, <footer>. Każdy znacznik daje Nano kontekst, którego nie da <div>. Strony zbudowane na divach są dla modelu zupą znaków. Strony zbudowane na semantyce są dla modelu mapą.
Schema.org. JSON-LD z @type: LocalBusiness, @type: Service, @type: Product mówi Nano dosłownie: „to jest firma, to jest jej oferta, to jest jej lokalizacja”. Bez tego model zgaduje. Z tym — wie.
llms.txt. To plik na poziomie domeny, który mówi modelowi językowemu, jak ma czytać twoją stronę i co ma być pierwszą informacją w streszczeniu. Standard świeży, ale Chrome (i inni) coraz częściej go uwzględnia. Generator iFox.pl/generator-llms tworzy go z istniejącej strony.
Te trzy rzeczy działają na trzy modele jednocześnie: na crawlerze Google, na agenta Claude in Chrome i na Nano w pasku adresu. To samo wejście, trzy różne wyjścia, jedna inwestycja. Korzyść skalowa jest po stronie tych, którzy zainwestują wcześniej.
Co z SEO i Google Search?
Tu trzeba zrobić rozróżnienie, bo Chrome 147 ma dwie różne powierzchnie AI, które wyglądają podobnie ale są zupełnie inne:
- Pigułka „AI Mode” w pasku adresu → to jest chmurowy Search Generative Experience od Google. Każde zapytanie jedzie na serwer Google. To nie używa lokalnego Nano. To jest klasyczne SGE, tylko wyciągnięte przed wynik wyszukiwania.
- Funkcje „Help me write”, podsumowywanie, smart paste → to jest lokalny Gemini Nano, działający na twojej maszynie z
weights.bin. Nie wysyła zapytań do Google.
Z punktu widzenia twojej strony:
- AI Mode w pasku adresu wpływa na to, jak Google opowiada o tobie w wynikach wyszukiwania, zanim człowiek na ciebie kliknie. To kontrolujesz przez klasyczny GEO (Generative Engine Optimization) — schema.org, treść strukturalna, dobre opisy.
- Nano lokalny wpływa na to, jak Chrome opowiada o tobie już na twojej stronie, kiedy człowiek na nią wszedł. To kontrolujesz przez agent-readiness — semantykę HTML, jasność treści, llms.txt.
Pierwsze widzisz w analytics jako spadek CTR. Drugie widzisz… nigdzie. Bo to się dzieje na urządzeniu użytkownika i nie ma feedbacku do twojego serwera. Dowiadujesz się o tym tylko wtedy, kiedy ktoś ci napisze: „przepraszam, myślałem że jesteście mniejszą firmą” — bo tak go zorientował Nano w podsumowaniu.
Co zrobić — pięć rzeczy, dziś
- Sprawdź agent-readiness swojej strony. Skaner na iFox.pl pokaże ci, jak strona jest „widoczna” dla modelu — semantyka, struktura, brakujące tagi, brakujące metadane.
- Dodaj llms.txt do domeny. Wpis w
/llms.txtmówi modelowi w pierwszej kolejności, kim jesteś, co robisz i co ma zostać podsumowane jako twoja strona. Bez tego Nano podsumowuje z tytułu, nagłówków i tagów meta — czyli z tego, co napisaliście pod algorytm Google z 2015 roku. Generator: iFox.pl/generator-llms. - Sprawdź swoje schema.org. Większość stron ma
WebSitei nic więcej. DodajLocalBusiness,Service,Product,FAQPage,Article— zależnie od typu strony. Generator: iFox.pl/generator-schema. - Przejrzyj nagłówki H1–H3. Jeden H1 na stronę. Hierarchia kompletna. Treść nagłówka odpowiada na konkretne pytanie. Nano używa nagłówków jako struktury podsumowania — jeśli nagłówki są generyczne („Nasze usługi”, „O nas”), podsumowanie też.
- Przetestuj, jak Nano widzi twoją stronę. W Chrome z włączonymi funkcjami AI (z
chrome://flags/#prompt-api-for-gemini-nanoustawionym na Enabled) możesz przez DevTools wywołaćwindow.ai.createTextSession()i kazać modelowi podsumować bieżącą stronę. To co dostaniesz, jest tym, co dostanie twój użytkownik, kiedy kliknie „Summarize this page”. Jeśli to podsumowanie cię nie reprezentuje — masz pracę do zrobienia.
Powrót do listopadowego pytania
W listopadzie 2025 zapytałem: czy web design ma jeszcze sens, jeśli agent ogląda stronę za użytkownika?
Pół roku później odpowiedź wygląda tak: web design ma teraz dwa cele, nie jeden. Pierwszym jest człowiek, który ostatecznie podejmie decyzję. Drugim — pierwszym czasowo, ale drugim w hierarchii ważności — jest model w przeglądarce użytkownika, który steruje tym, jak człowiek twoją stronę odczyta.
Strony, które ignorują drugiego czytelnika, będą wyglądać dobrze w Figmie i robić słabe konwersje w 2027. Strony, które ignorują pierwszego, będą czytelne dla AI i nudne dla ludzi. Strony, które rozumieją obu — wygrają.
To nie jest dramatyczna zmiana. To jest po prostu nowa warstwa. Dwadzieścia lat temu dodaliśmy mobile. Dziesięć lat temu dodaliśmy accessibility. Teraz dodajemy AI-readiness. Każda z tych warstw na początku wyglądała jak komplikacja. Każda po roku stała się oczywistym standardem.
Różnica jest taka, że tym razem warstwa przyszła sama, na 500 milionów urządzeń, w 14 minut i 28 sekund, bez pytania. Możesz na to narzekać (i mamy pełną analizę prawną na CyberFlux, dla tych, którzy chcą narzekać konkretnie). Możesz też potraktować to jako fakt rynkowy i działać.
Twoja strona ma od teraz pierwszego czytelnika. Nie jest nim człowiek. Zaprojektuj ją tak, żeby go nie obraziła — bo to on zdecyduje, co o tobie powie człowiekowi, którego naprawdę chciałeś.
Powiązane wpisy:
- Salon kosmetyczny kontra Claude in Chrome — eksperyment z agent-readiness
- Atlas od OpenAI — 6 miesięcy później
- Przeglądarki AI w 2026 — przegląd
- Analiza techniczna i prawna — CyberFlux
Narzędzia, które warto odpalić:
- Skaner agent-readiness — sprawdź, jak twoja strona wygląda z perspektywy modelu
- Generator llms.txt
- Generator schema.org