Prompt to jedno zdanie.
Kontekst to wszystko, co model widzi, zanim odpowie.
Przez dwa lata uczyliśmy się pisać dobre prompty. Dobierać słowa, dodawać „myślmy krok po kroku”, wklejać przykład albo dwa. I to działało — bo rozmawialiśmy z chatbotem. Jeden prompt, jedna odpowiedź. Te eksperymenty — co da się osiągnąć, jak utrzymać powtarzalność i namiastkę determinizmu, kiedy LLM podejmuje własne makrodecyzje — prowadzimy na promptujemy.pl. Ale agent to już inny układ.
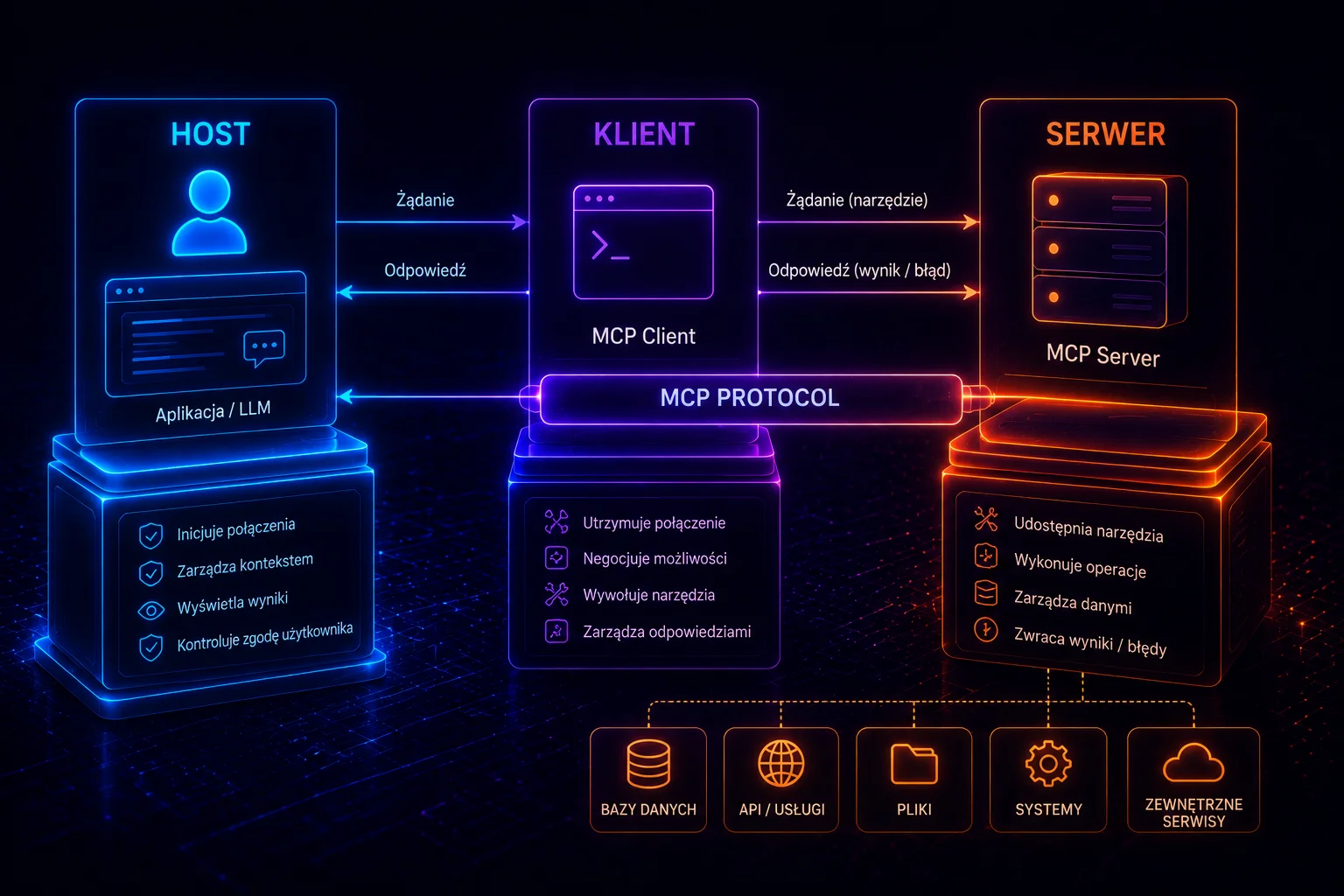
Agent nie rozmawia. Agent działa w pętli, wywołuje narzędzia, czyta wyniki, sięga do pamięci i wraca do początku — dopóki zadanie nie jest skończone. Przy każdej iteracji model dostaje nie „pytanie”, tylko całe okno: instrukcję systemową, historię tego, co już zrobił, wynik ostatniego narzędzia, pobrane dane, przykłady. I to, czy agent zadziała, rozstrzyga się nie w sformułowaniu jednego zdania, ale w tym, co i w jakiej kolejności trafia do tego okna.
To jest context engineering. I to jest powód, dla którego „lepszy prompt” przestał być właściwym pytaniem.
Prompt engineering rozwiązał wczorajszy problem
Nie chodzi o to, że prompt engineering był błędem. Był odpowiedzią na konkretny układ: człowiek pisze, model odpowiada, koniec. W takim układzie cała gra toczy się o jedno wejście, więc szlifowanie tego wejścia ma sens.
Problem w tym, że ten układ to dziś margines. Gdy budujesz agenta — choćby pierwszy przepływ w n8n, który czyta maila, sprawdza coś w bazie i wystawia odpowiedź — nie masz „jednego promptu”. Masz sekwencję wywołań modelu, w której każde kolejne dostaje na wejściu to, co wyprodukowały poprzednie.
Agent nie pyta — agent działa w pętli. Jeśli nie wiesz, jak ta pętla wygląda od środka, zacznij od tego, jak agent myśli — ReAct, chain-of-thought i pętla, która nigdy nie śpi. Tu zakładamy, że pętla jest jasna, i pytamy o coś innego: czym karmisz model przy każdym jej obrocie.
Czym naprawdę jest context engineering
Najprościej: context engineering to projektowanie tego, co znajdzie się w oknie kontekstu modelu w danym momencie — żeby model miał dokładnie to, czego potrzebuje, i nic poza tym.
Dwie rzeczy są tu nieoczywiste i obie zmieniają sposób pracy.
Okno kontekstu to budżet, nie worek. Pokusa jest oczywista: skoro model „lepiej rozumie z kontekstem”, to wrzućmy wszystko — całą historię, całą dokumentację, wszystkie wyniki. To intuicja, która psuje agenty. Okno ma skończony rozmiar i skończoną uwagę. Im więcej w nim wrzucisz, tym trudniej modelowi znaleźć to, co istotne — o degradacji jakości w zapchanym oknie piszemy osobno, w wpisie o oknie kontekstu i context rot. Na razie zapamiętaj zasadę: każdy token, który dodajesz, czemuś służy albo coś psuje. Trzeciej możliwości nie ma.
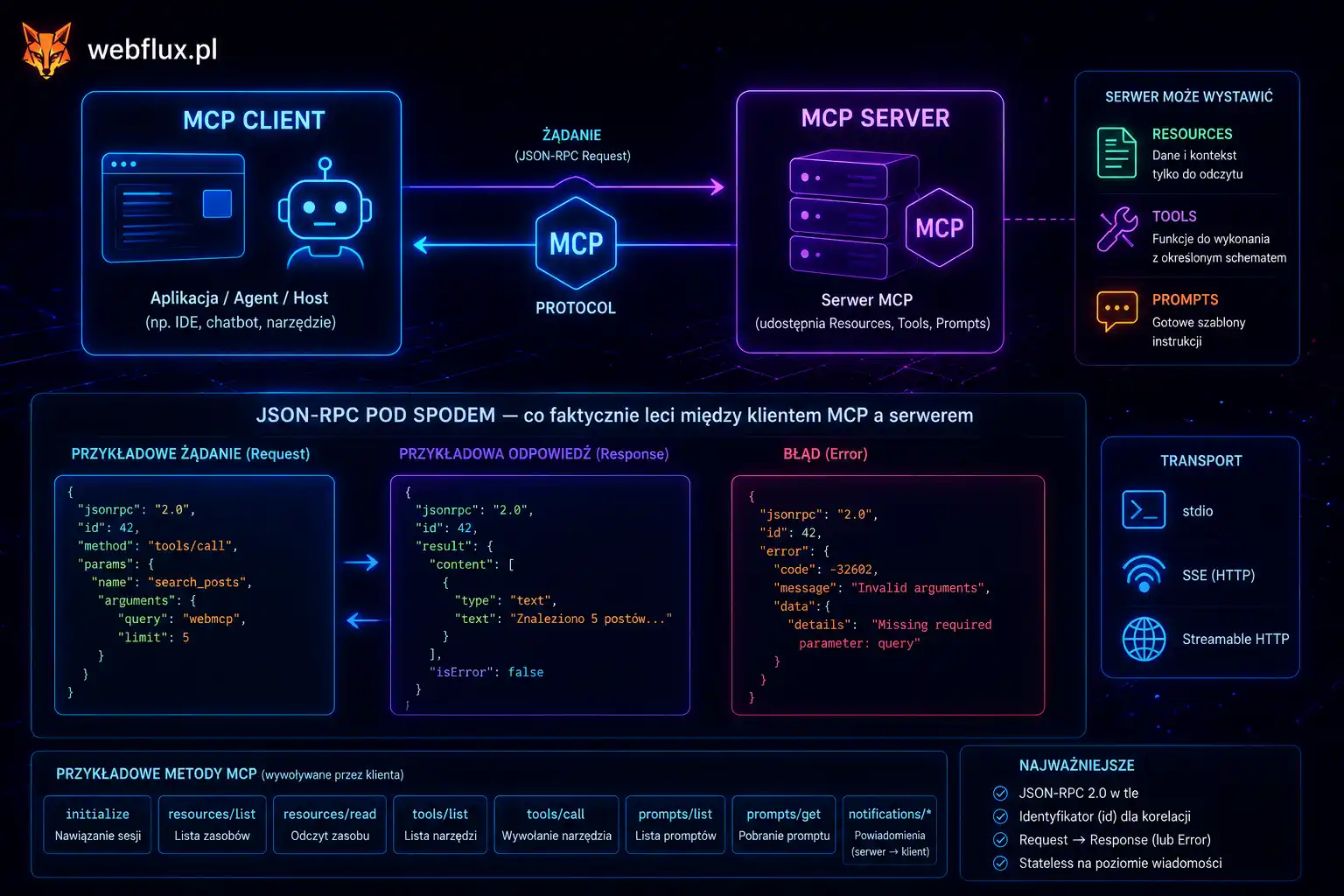
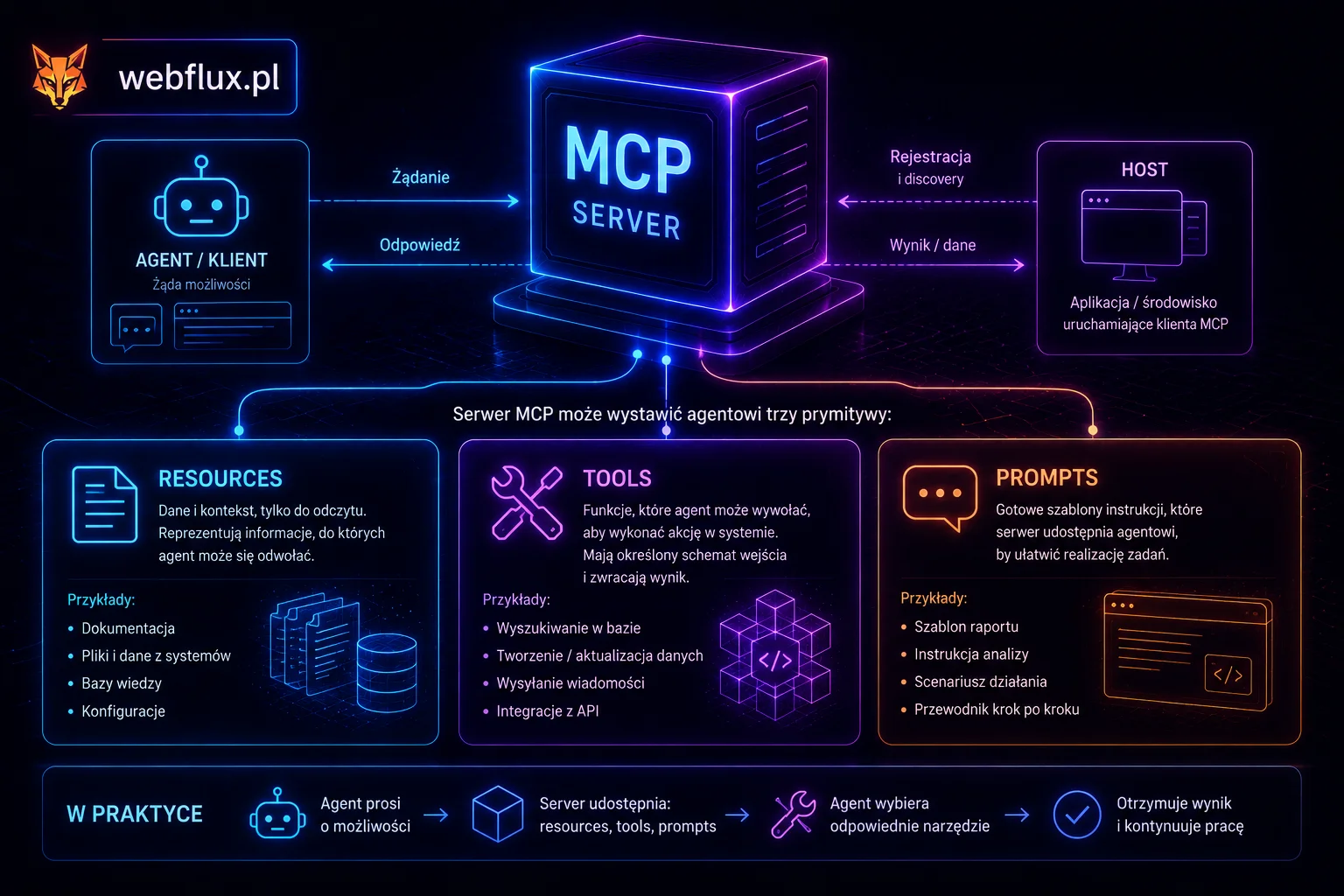
Kontekst ma warstwy. To, co model widzi, nie jest jednym blokiem tekstu. To kilka źródeł sklejonych w jedno okno:
- System prompt — kim agent jest, co wolno, czego nie. To fundament, ale tylko fundament. Dlaczego system prompt to nie to samo co pytanie, rozkłada na części osobny artykuł serii.
- Pamięć — co agent wie z wcześniejszych kroków i sesji. Czemu zły design pamięci wywraca agenta, pokazują cztery typy pamięci.
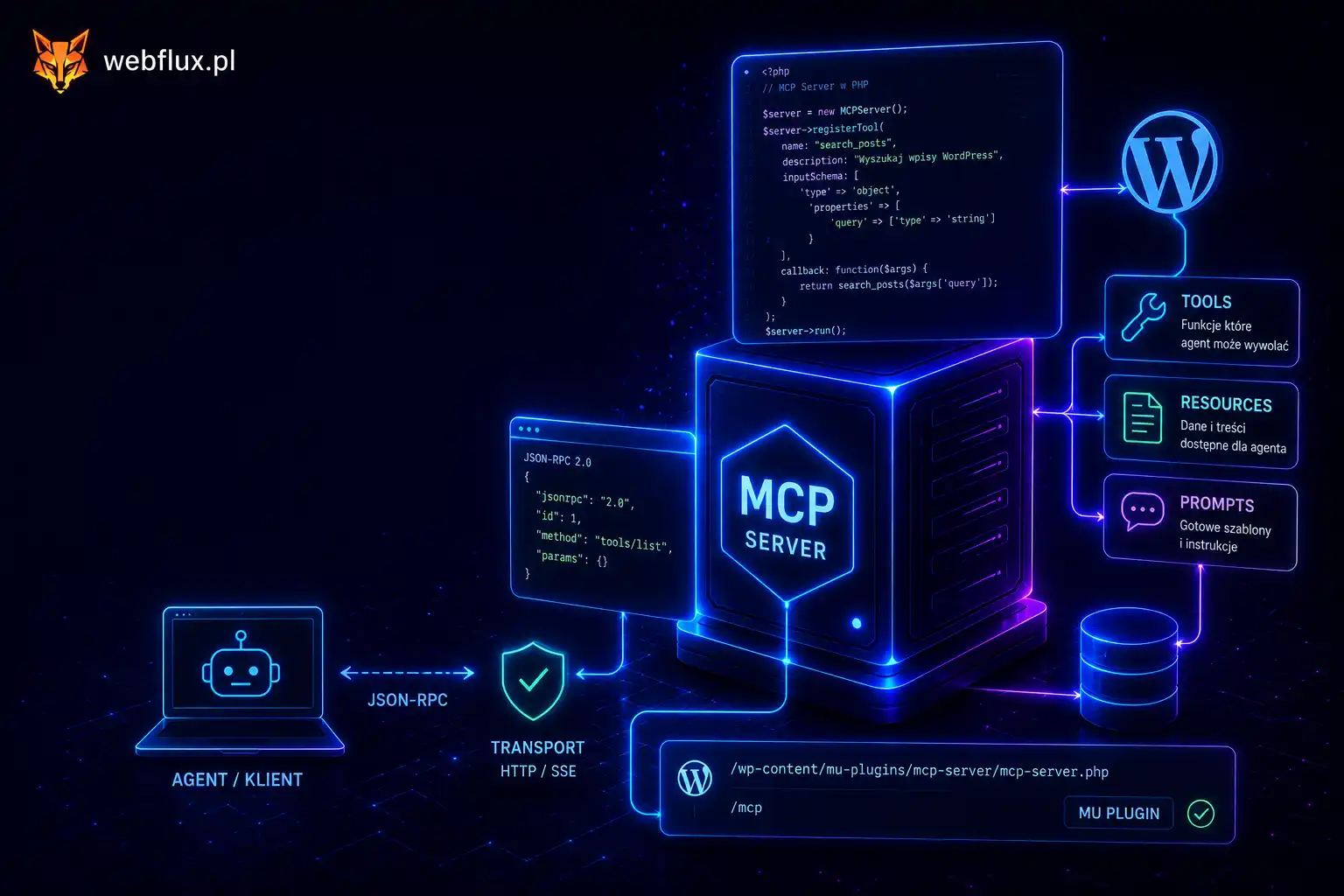
- Wyniki narzędzi — to, co wróciło z bazy, API, requestu HTTP. I to, w jakiej formie wróciło, decyduje, czy agent to wykorzysta.
- Retrieval — dane pobrane na potrzebę konkretnego kroku, zamiast trzymane w oknie na zapas. To rozwinięcie RAG od strony „co realnie ląduje w oknie”.
- Przykłady — few-shot, czyli wzorce pokazujące modelowi, czego od niego chcesz. Po głębię samego promptowania — powtarzalność, dobór przykładów, namiastka determinizmu — odsyłamy do promptujemy.pl; tu interesuje nas, jak te przykłady zmieszczą się w oknie obok reszty warstw.
Context engineering to decydowanie, które z tych warstw, ile z nich i w jakiej kolejności wchodzą do okna przy danym kroku. Prompt engineering zajmował się jedną z tych warstw. Context engineering zajmuje się ich kompozycją.
Dlaczego „więcej kontekstu” psuje agenta
Najczęstszy błąd przy pierwszym agencie nie jest błędem promptu. Jest błędem kompozycji: do okna wpada za dużo, za późno odcinane, w złej kolejności.
Wyobraź sobie agenta obsługi, który przy każdym kroku dostaje całą dotychczasową rozmowę, pełną dokumentację produktu i surowy dump z trzech wywołań API. Model „ma wszystko” — i właśnie dlatego gubi to jedno zdanie z maila klienta, które było istotne. Kluczowa informacja utonęła w środku długiego okna, między rzeczami, których przy tym kroku nie potrzebował.
To ma dwie ceny. Pierwsza to jakość — agent działa gorzej, im więcej go karmisz nieistotnym. Druga jest zupełnie wymierna: dłuższy kontekst to więcej tokenów przy każdej iteracji pętli, a pętla obraca się wiele razy. Jak szybko to rośnie i co z tym zrobić, liczy wpis o kosztach agenta w produkcji. Tu wystarczy konkluzja: rozdęty kontekst płaci się dwa razy — gorszym wynikiem i wyższym rachunkiem.
Dobry agent to nie ten, który „wie wszystko”. To ten, który przy każdym kroku widzi dokładnie to, co potrzebne — i nic więcej.
Od promptu do systemu: co się realnie zmienia
Przejście od prompt engineeringu do context engineeringu zmienia pytania, które sobie zadajesz przy budowie.
Zamiast „jak sformułować prompt, żeby model dobrze odpowiedział” — pytasz „co musi być w oknie przy tym konkretnym kroku, żeby model podjął dobrą decyzję”.
Zamiast „wrzućmy całą wiedzę do system promptu” — pytasz „co trzymać na stałe, co odciąć, a co pobrać dopiero wtedy, gdy będzie potrzebne”. To różnica między ładowaniem wszystkiego z góry a pobieraniem just-in-time — i ona realnie rozstrzyga o jakości i koszcie.
Zamiast „dodajmy przykład” — pytasz „które przykłady, dla którego kroku, i czy nie zajmują miejsca, które przyda się na coś ważniejszego”.
Granica jest prosta do zapamiętania. System prompt to projektowanie jednej warstwy, na stałe. Context engineering to projektowanie całego okna, dynamicznie, krok po kroku. Pierwsze jest częścią drugiego — nie jego alternatywą.
Co to zmienia dla kogoś, kto buduje agenta
Jeśli składasz agenta — w n8n, w kodzie, gdziekolwiek — context engineering daje trzy konkretne nawyki.
Traktuj okno jak budżet. Przed każdym krokiem wiedz, co w nim jest i po co. Jeśli czegoś nie umiesz uzasadnić, to prawdopodobnie szum, który psuje wynik i podbija rachunek.
Odcinaj i pobieraj zamiast gromadzić. Nie trzymaj w oknie wszystkiego „na wszelki wypadek”. Streszczaj historię, gdy rośnie. Pobieraj dane dopiero, gdy krok ich wymaga. Formatuj wyniki narzędzi tak, żeby były gotowym kontekstem, a nie surowym dumpem do przekopania.
Projektuj kompozycję, nie zdania. Twoja robota to nie „napisać dobry prompt”. To zdecydować, które warstwy kontekstu, w jakiej kolejności i w jakiej formie składają się na okno przy danym obrocie pętli.
To jest cała sekcja, którą tu otwieramy. Pillar nazwał problem — kolejne wpisy rozkładają go na części: budżet okna i context rot, warstwy kontekstu w praktyce, retrieval just-in-time, kompakcja przy długich przebiegach, few-shot, formatowanie wyników narzędzi. Zacznij od dowolnego — każdy jest samodzielny, każdy wraca do tej samej zasady: agent jest tak dobry, jak kontekst, który mu składasz.
Pojęcia ze słownika: Context engineering · Okno kontekstu · Context rot · Budżet tokenów · Lost in the middle · Few-shot · Just-in-time retrieval · System prompt vs user prompt