Spis treści
Artykuł 1 — czym jest agent-readiness i dlaczego większość stron WordPress startuje z 0/100
Artykuł 2 —
rel="service-doc", strona/dla-agentowi pułapka LiteSpeed cacheArtykuł 3 — Markdown for Agents bez Cloudflare Pro i krytyczna pułapka z
Vary: AcceptArtykuł 4 — Content Signals w robots.txt i dlaczego kolejność dyrektyw ma znaczenie
Artykuł 5 — JSON API z WordPress CPT i dwa domyślne błędy REST API
Artykuł 6 — diagnostyka przez curl, pełny raport w jednej chwili
W poprzednich artykułach daliśmy agentom mapę serwisu, efektywne serwowanie treści i deklarację co im wolno. Agent który trafi na webflux.pl wie gdzie szukać, dostaje Markdown zamiast HTML i wie że może cytować nasze treści.
Ale do tej pory agent był tylko czytnikiem. Przychodził, pobierał stronę, odchodził.
Następny poziom to agenci którzy nie tylko czytają — ale odpytują. Szukają konkretnych danych, filtrują, porównują. Do tego potrzebują nie strony HTML, ale ustrukturyzowanego endpointu.
I tu wchodzi REST API WordPress.
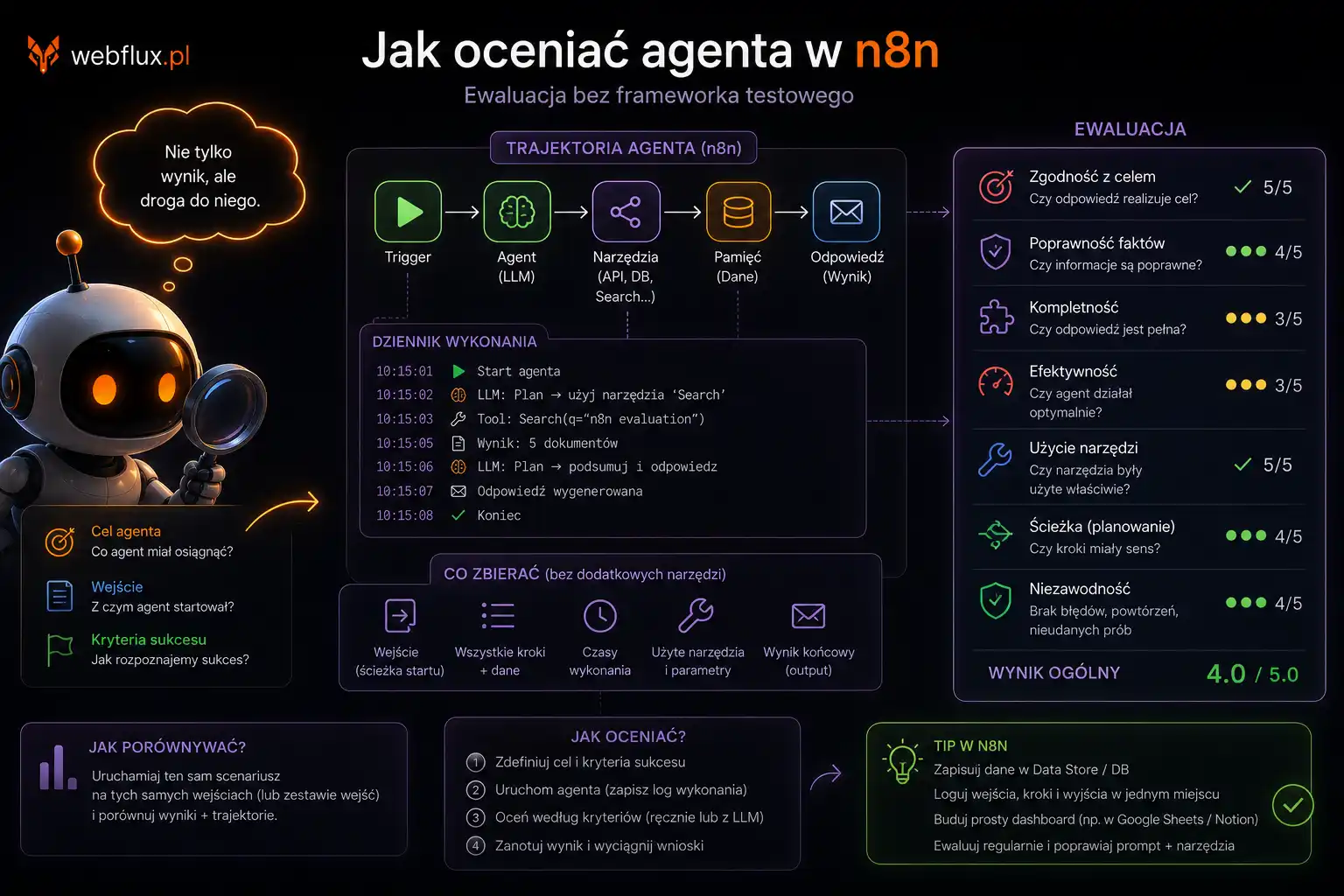
Kiedy JSON API dla agentów ma sens
Nie każda strona potrzebuje własnego API. Ma sens gdy masz zbiór danych który agent mógłby chcieć przeszukać lub przefiltrować:
- Słownik pojęć — „daj mi wszystkie terminy z kategorii Protokoły”
- Katalog produktów — „jakie produkty są dostępne w cenie do X”
- Baza zasobów — „pokaż mi artykuły o bezpieczeństwie agentów”
- Lista usług — „co oferujesz dla sklepów WooCommerce”
WebFlux.pl ma słownik 44 pojęć Agentic Web — każde z definicją, polską nazwą, wariantami i przypisaniem do klastra tematycznego. Zamiast zmuszać agenta do scrapowania 44 osobnych stron — wystawiamy jeden endpoint który zwraca wszystko w czystym JSON.
Efekt: agent pobiera jeden request zamiast 44. Dostaje ustrukturyzowane dane zamiast HTML. Wie jak filtrować bo zna schemat.
Architektura endpointu
WordPress REST API pozwala zarejestrować własne endpointy przez register_rest_route. Endpoint jest dostępny pod:
https://twoja-strona.pl/wp-json/twoja-przestrzen/v1/nazwa-endpointuDla agentów endpoint powinien zwracać dane w schemacie który agent może przewidzieć — stałe nazwy pól, konsekwentne typy, żadnych niespodzianek.
Dobry schemat dla słownika pojęć wygląda tak:
[
{
"term": "Agent AI",
"slug": "agent-ai",
"url": "https://webflux.pl/slownik/agent-ai/",
"definition": "Autonomiczny system sztucznej inteligencji...",
"polska_nazwa": "Agent AI",
"warianty": ["agent sztucznej inteligencji", "agenty AI"],
"content": "Pełna treść pojęcia...",
"cluster": ["Fundamenty"],
"updated": "2026-04-21T18:29:29+02:00"
}
]Każde pole ma jasne znaczenie. Agent który pierwszy raz widzi ten endpoint — od razu wie co zawiera definition, czym różni się od content, co to są warianty.
Dwie rzeczy które WordPress robi źle domyślnie
Tu zaczyna się część której nie znajdziesz w dokumentacji WordPress REST API — dwa domyślne zachowania które blokują agentów zanim w ogóle zaczną.
Problem 1: x-robots-tag: noindex
WordPress automatycznie dodaje do wszystkich odpowiedzi REST API nagłówek:
x-robots-tag: noindexTo jest celowe — WordPress nie chce żeby endpointy REST API były indeksowane przez wyszukiwarki. Ma to sens dla większości endpointów które zawierają dane techniczne, tokeny, metadane.
Ale dla endpointu który celowo wystawiamy dla agentów — noindex jest problemem. Część crawlerów i agentów AI respektuje ten nagłówek i odmawia przetworzenia odpowiedzi. Twój endpoint istnieje, zwraca dane, ale agent go ignoruje.
Rozwiązanie: nadpisać nagłówek dla konkretnego endpointu żeby zwracał index, follow zamiast noindex.
Problem 2: Disallow: /wp-json/ w robots.txt
O tym pisałem w poprzednim artykule — domyślny Yoast blokuje cały REST API. Jeśli nie dodałeś Allow dla swojego endpointu przed Disallow: /wp-json/ — agent nie dotrze do niego nawet jeśli zna adres.
Weryfikacja że oba problemy są naprawione:
# Sprawdź nagłówki endpointu
curl -sI https://twoja-strona.pl/wp-json/twoja-przestrzen/v1/slownik | grep -E "content-type|x-robots"
# Oczekiwany wynik:
# content-type: application/json; charset=UTF-8
# x-robots-tag: index, follow ← nie "noindex"# Sprawdź robots.txt
curl -s https://twoja-strona.pl/robots.txt | grep -E "Allow|Disallow" | head -5
# Oczekiwany wynik:
# Allow: /wp-json/twoja-przestrzen/v1/slownik ← przed Disallow
# Disallow: /wp-json/Dokumentuj endpoint w /dla-agentow
Sam endpoint nie wystarczy — agent musi wiedzieć że istnieje.
Wróć do strony /dla-agentow i dodaj sekcję:
## JSON API — dane strukturalne
Endpoint: https://twoja-strona.pl/wp-json/twoja-przestrzen/v1/slownik
Format: application/json
Metoda: GET
Aktualizacja: automatyczna przy każdej zmianie
Pola: term, slug, url, definition, polska_nazwa, warianty, content, cluster, updatedAgent który przychodzi przez rel="service-doc" → /dla-agentow → widzi endpoint → odpytuje go. Pełna ścieżka odkrycia bez zgadywania.
Ile to robi różnicy w praktyce
Sprawdziłem endpoint webflux.pl po wdrożeniu — zwraca 44 pojęcia z pełnymi treściami, definicjami i metadanymi w jednym requeście.
Agent który chce odpowiedzieć na pytanie „jakie protokoły handlu agentowego opisuje webflux.pl” bez endpointu musiałby:
- pobrać stronę słownika (JavaScript — niewidoczna dla agenta)
- odgadnąć że istnieją podstrony
/slownik/nazwa-pojecia/ - pobrać każdą z 44 podstron osobno
- wyfiltrować te z kategorii „Protokoły i standardy”
Z endpointem: jeden request, filtrowanie po polu cluster, gotowe.
Nie chcesz pisać tego samemu?
Budowa endpointu to kilkadziesiąt linii PHP — obsługa register_rest_route, pobieranie danych z CPT, mapowanie taksonomii na pola JSON, naprawienie x-robots-tag.
Całość — razem z automatyczną dokumentacją endpointu w /dla-agentow i panelem konfiguracyjnym — jest częścią pluginu Agent-Ready WP dostępnego wkrótce na iFox.pl.
Plugin wykrywa Twoje Custom Post Types i pozwala wybrać które z nich wystawić jako endpoint dla agentów. Bez pisania kodu, bez ryzyka że coś się posypie po aktualizacji WordPress.
Efekt końcowy
Po wdrożeniu endpointu i naprawieniu obu domyślnych problemów WordPress — agenci mają pełny dostęp do ustrukturyzowanych danych Twojego serwisu.
Cloudflare checker w kategorii API & Skill Discovery zacznie pokazywać punkty — ale ważniejsze jest że realne agenty które szukają informacji z Twojej dziedziny mają teraz coś czego nie dają im inne strony: dane gotowe do przetworzenia.
Co dalej
Masz wdrożone wszystkie cztery warstwy agent-readiness. Ostatnie pytanie brzmi: skąd wiesz że to naprawdę działa?
Przeglądarka pokazuje stronę tak jak ją widzi człowiek. Agent widzi coś zupełnie innego. W ostatnim artykule serii pokazuję jak myśleć jak agent i jak sprawdzić przez curl wszystko czego nie widać w przeglądarce — w pięć minut, bez żadnych narzędzi poza terminalem.
Ten artykuł jest częścią serii „WordPress Agent-Readiness”. Wszystkie wdrożenia zostały przetestowane na webflux.pl — włącznie z błędami i ich naprawą.