Artykuł 1 — czym jest agent-readiness i dlaczego większość stron WordPress startuje z 0/100
Artykuł 2 —
rel="service-doc", strona/dla-agentowi pułapka LiteSpeed cacheArtykuł 3 — Markdown for Agents bez Cloudflare Pro i krytyczna pułapka z
Vary: AcceptArtykuł 4 — Content Signals w robots.txt i dlaczego kolejność dyrektyw ma znaczenie
Artykuł 5 — JSON API z WordPress CPT i dwa domyślne błędy REST API
Artykuł 6 — diagnostyka przez curl, pełny raport w jednej chwili
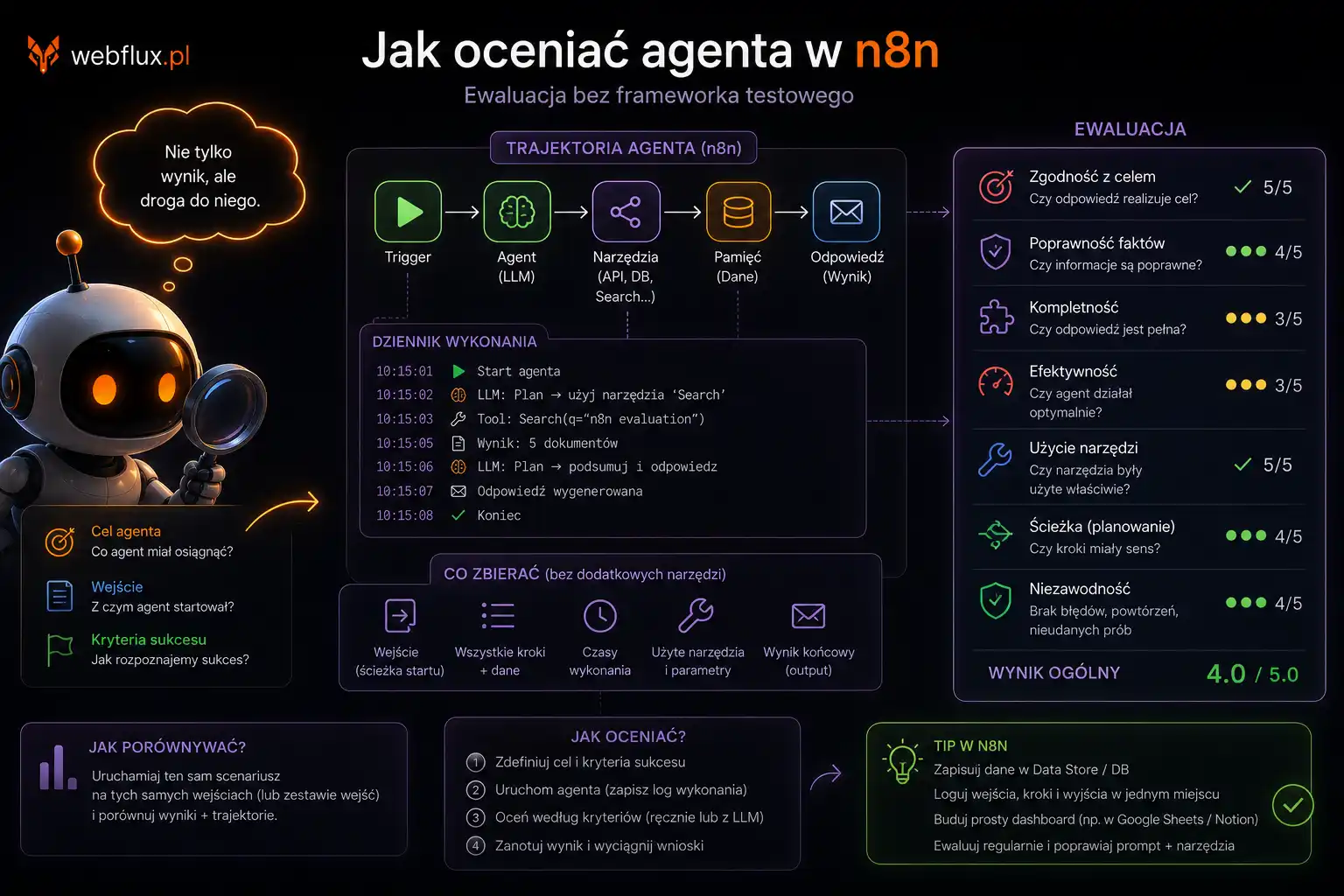
W poprzednim artykule opisałem czym jest agent-readiness i dlaczego większość stron WordPress startuje z wynikiem 0/100. Dziś wdrażamy pierwszy i najważniejszy sygnał — nagłówek rel="service-doc" i stronę /dla-agentow która jest za nim.
To jest punkt od którego zaczyna się każda rozmowa agenta z Twoim serwisem.
Co agent robi zanim zacznie czytać
Wyobraź sobie że agent dostaje zadanie: „znajdź informacje o agent-readiness WordPress”. Trafia na webflux.pl. Pierwsza rzecz którą robi — sprawdza nagłówki HTTP odpowiedzi serwera.
Nagłówki HTTP to metadane które serwer wysyła przed treścią strony. Przeglądarka je przetwarza cicho w tle. Agent — aktywnie szuka w nich sygnałów.
Jeden z tych sygnałów to nagłówek Link z relacją service-doc:
Link: </dla-agentow>; rel="service-doc"Ten nagłówek mówi agentowi: „hej, mam dla Ciebie dedykowaną stronę która opisuje ten serwis — zajrzyj tam zanim zaczniesz szukać na własną rękę.”
To odpowiednik tablicy informacyjnej przy wejściu do budynku. Zamiast błądzić po korytarzach — agent idzie prosto do źródła.
Dwa kroki do Discoverability 100/100
Żeby dostać 100 punktów w kategorii Discoverability potrzebujesz dwóch rzeczy:
- Nagłówek HTTP
Link: </dla-agentow>; rel="service-doc"wysyłany przez serwer - Strona
/dla-agentowz czytelnym indeksem serwisu
Brzmi prosto. I jest proste — ale po drodze jest jedna pułapka która potrafi zmarnować kilka godzin. Zaraz do niej dojdziemy.
Krok 1: Nagłówek service-doc
Pierwsza próba — WordPress filter
Naturalne rozwiązanie w WordPress to hook wp_headers. Dodajesz do functions.php:
add_filter('wp_headers', function ($headers) {
if (is_front_page() || is_home()) {
$headers['Link'] = '</dla-agentow>; rel="service-doc"';
}
return $headers;
});Wygląda dobrze. Zapisujesz, sprawdzasz w przeglądarce — wszystko normalnie. Sprawdzasz narzędziem Cloudflare — nadal 0 punktów. Sprawdzasz nagłówki przez curl:
curl -sI https://twoja-strona.pl/ | grep -i linkNic. Nagłówek nie istnieje.
Pułapka: LiteSpeed Cache
Jeśli Twój hosting używa LiteSpeed (a większość polskich hostingów tak) — masz problem którego nie widać w panelu.
LiteSpeed Cache serwuje stronę główną z cache, całkowicie pomijając PHP. Filtr wp_headers nigdy nie jest wywoływany bo WordPress w ogóle nie startuje — LiteSpeed odpowiada bezpośrednio z zapisanej kopii.
Diagnoza jest prosta — w nagłówkach odpowiedzi zobaczysz:
x-litespeed-cache: hithit oznacza że odpowiedź pochodzi z cache. PHP nie było uruchamiane. Twój filter nie istnieje.
Rozwiązanie: Cloudflare Transform Rules
Zamiast walczyć z LiteSpeed — obejdź go. Dodaj nagłówek na poziomie Cloudflare, przed tym jak odpowiedź dotrze do przeglądarki czy agenta.
- Cloudflare Dashboard → Rules → Transform Rules → Modify Response Header
- Nowa reguła:
- When:
URI Path equals / - Action: Add header
- Name:
Link - Value:
</dla-agentow>; rel="service-doc"
- When:
- Zapisz i wdróż
Cloudflare dodaje nagłówek do każdej odpowiedzi ze strony głównej — niezależnie od tego czy LiteSpeed serwuje z cache czy nie.
Weryfikacja:
curl -sI https://twoja-strona.pl/ | grep -i link
# → link: </dla-agentow>; rel="service-doc"Jedna uwaga: Cloudflare może automatycznie dodać trailing slash do URL w nagłówku — </dla-agentow/> zamiast </dla-agentow>. Technicznie bez znaczenia (oba URLe działają), ale jeśli chcesz czysty zapis — wpisz w wartości nagłówka </dla-agentow> bez slasha i sprawdź wynik.
Krok 2: Strona /dla-agentow
Nagłówek mówi agentowi gdzie szukać. Strona /dla-agentow musi mu powiedzieć co znajdzie.
Co musi zawierać ta strona
Agent nie potrzebuje pięknego layoutu. Potrzebuje ustrukturyzowanej informacji którą może przetworzyć bez renderowania JavaScriptu.
Minimalna zawartość:
Opis serwisu — czym jest, dla kogo, jaka jest główna idea. Kilka zdań, bez marketingowego żargonu.
Główne huby tematyczne — z bezpośrednimi URL-ami. Nie „sprawdź naszą sekcję SEO” — tylko https://twoja-strona.pl/seo-i-widocznosc/.
Wyspecjalizowane ścieżki — jeśli masz serie artykułów, słowniki, bazy wiedzy — każda z bezpośrednim linkiem.
Wskazówki interpretacyjne — czy treści są poradnikowe, analityczne, eksperckie? Czy opisują standardy przyjęte powszechnie czy Twoje własne interpretacje? Agent który to wie — lepiej cytuje.
Właściciel serwisu — imię, kontakt, powiązane serwisy. To sygnał wiarygodności dla agentów które oceniają provenance treści.
Jak zbudować stronę w WordPress
Utwórz nową stronę (Strony → Dodaj nową) z permalink /dla-agentow. Treść pisz w zwykłym edytorze — bez shortcode’ów, bez fancy bloków które renderują się przez JavaScript.
Dlaczego to ważne: agent pobiera HTML strony i przetwarza tekst. Treść która siedzi w JavaScript — dla agenta nie istnieje. Divi, Elementor, WPBakery — wszystkie te buildery mogą generować treść przez JS jeśli nie uważasz.
Najbezpieczniejsza opcja: klasyczny blok „Paragraf” i „Nagłówek” w Gutenbergu, albo moduł tekstowy Divi z czystym HTML.
Sprawdź czy agent to widzi:
curl -s https://twoja-strona.pl/dla-agentow/ | grep -i "nazwa-twojego-serwisu"Jeśli tekst który wpisałeś pojawia się w wynikach — agent go widzi. Jeśli nie — treść jest w JavaScript.
Pułapka: podwójny H1
WordPress generuje H1 z tytułu strony. Jeśli w treści też dodasz H1 — masz dwa nagłówki H1 na jednej stronie. To słaby sygnał strukturalny dla agentów (i dla SEO).
Rozwiązanie: ukryj tytuł strony. W Divi → ustawienia strony → ukryj tytuł. W Gutenbergu → prawy panel → ustaw tytuł jako wizualnie ukryty. Albo po prostu zmień tytuł strony na neutralny (Agent Index) i zostaw H1 w treści.
Efekt końcowy
Po wdrożeniu obu kroków — curl powinien zwrócić:
# Nagłówek service-doc
curl -sI https://twoja-strona.pl/ | grep -i link
# → link: </dla-agentow>; rel="service-doc"
# Strona dostępna i czytelna
curl -s https://twoja-strona.pl/dla-agentow/ | head -50
# → [treść strony w HTML, bez JavaScriptu]A wynik w Cloudflare checker:
Discoverability: 100/100 ✓
Co dalej
Masz już sygnał dla agentów i mapę serwisu. Agent który trafi na Twoją stronę wie że jesteś przygotowany na jego wizytę i wie gdzie szukać.
Kolejny krok to upewnienie się że gdy agent zacznie czytać treść — dostanie ją w formacie który mu nie marnuje kontekstu. Czyli Markdown zamiast HTML.
W następnym artykule implementujemy Markdown for Agents bezpośrednio w WordPress — bez Cloudflare Pro. I opisuję pułapkę która może sprawić że Twoja strona zacznie serwować Markdown wszystkim użytkownikom zamiast tylko agentom.
Ten artykuł jest częścią serii „WordPress Agent-Readiness”. Wszystkie wdrożenia zostały przetestowane na webflux.pl — włącznie z błędami i ich naprawą.