Przeglądarka kłamie.
Nie złośliwie — po prostu robi swoją robotę. Renderuje JavaScript, ukrywa nagłówki HTTP, przetwarza przekierowania w tle, cache’uje odpowiedzi. Pokazuje Ci stronę tak jak ją widzi człowiek.
Agent widzi coś zupełnie innego.
Gdy chcesz sprawdzić czy Twoja strona jest naprawdę gotowa na agentów — przeglądarka jest złym narzędziem. Potrzebujesz czegoś co zachowuje się jak agent: pobiera surowe odpowiedzi HTTP, pokazuje nagłówki, nie renderuje JavaScriptu, nie cache’uje.
To narzędzie nazywa się curl. Jest dostępne na każdym systemie, nie wymaga instalacji na Macu i Linuxie, i w pięć minut powie Ci więcej o agent-readiness Twojej strony niż godzina klikania w przeglądarce.
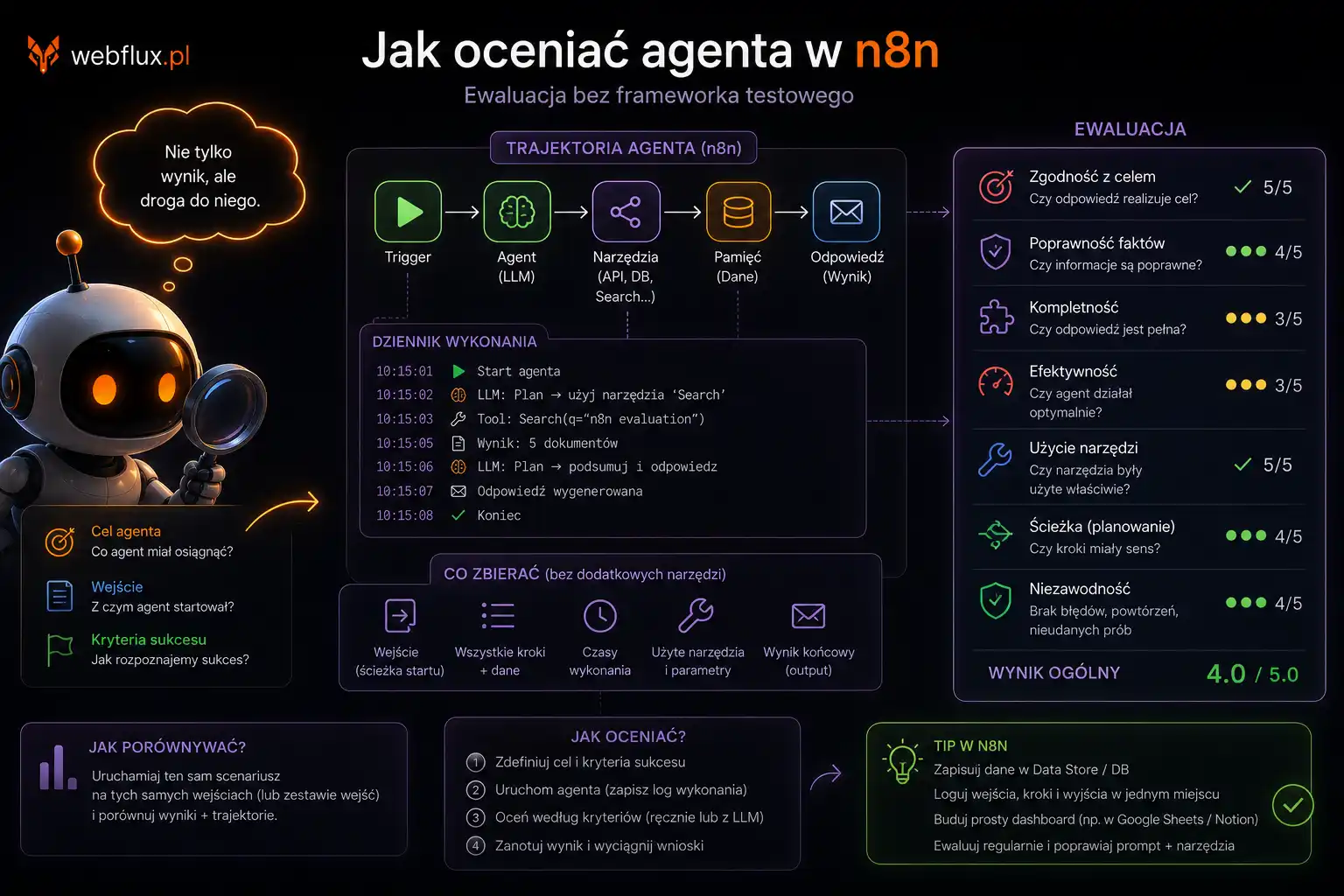
Zanim zaczniesz — jak czytać wyniki curl
Dwie flagi których będziesz używać najczęściej:
-s — silent, wycisza pasek postępu. Bez tego curl wyświetla informacje o transferze które zaśmiecają wyniki.
-I — pobiera tylko nagłówki HTTP, bez treści strony. Szybko i czytelnie.
Kombinacja -sI to podstawa diagnostyki:
curl -sI https://twoja-strona.pl/Wynik to lista nagłówków — każda linia to jeden nagłówek. Szukasz konkretnych wartości.
Komenda 1: czy service-doc header jest wysyłany
curl -sI https://twoja-strona.pl/ | grep -i linkOczekiwany wynik:
link: </dla-agentow>; rel="service-doc"Jeśli nic nie zwraca: nagłówek nie jest wysyłany. Sprawdź czy Cloudflare Transform Rule jest aktywna i czy dotyczy właściwej domeny.
Jeśli zwraca z trailing slash: </dla-agentow/> zamiast </dla-agentow> — technicznie działa, ale możesz poprawić w ustawieniach Transform Rule.
Dlaczego nie wp_headers filter: jeśli widzisz x-litespeed-cache: hit w nagłówkach — LiteSpeed serwuje z cache i PHP nie jest uruchamiane. Filter WordPress nigdy nie odpala. Cloudflare Transform Rule to właściwe rozwiązanie.
Komenda 2: czy Markdown for Agents działa poprawnie
To są dwie komendy — obie musisz wykonać i oba wyniki muszą być właściwe.
# Agent pyta o Markdown — powinien dostać Markdown
curl -sI https://twoja-strona.pl/artykul/ -H "Accept: text/markdown" | grep content-typeOczekiwany wynik:
content-type: text/markdown; charset=utf-8# Przeglądarka nie pyta o Markdown — powinna dostać HTML
curl -sI https://twoja-strona.pl/ | grep content-typeOczekiwany wynik:
content-type: text/html; charset=UTF-8Jeśli oba zwracają text/markdown: LiteSpeed zacachował wersję Markdown i serwuje ją wszystkim. To jest krytyczny błąd — Twoja strona wygląda jak surowy tekst dla wszystkich użytkowników. Natychmiast wyczyść cache LiteSpeed i upewnij się że w kodzie jest nagłówek X-LiteSpeed-Cache-Control: no-cache, no-store dla odpowiedzi Markdown.
Jeśli pierwszy zwraca text/html zamiast text/markdown: implementacja Markdown for Agents nie działa. Sprawdź czy kod jest w aktywnym motywie lub mu-pluginie i czy hook template_redirect odpala się z priorytetem 1.
Możesz też sprawdzić jak wygląda sama treść Markdown:
curl -s https://twoja-strona.pl/artykul/ -H "Accept: text/markdown" | head -20Powinieneś zobaczyć YAML frontmatter z tytułem i URL, a po nim treść artykułu bez tagów HTML.
Komenda 3: czy robots.txt jest poprawny
curl -s https://twoja-strona.pl/robots.txtSprawdzasz cztery rzeczy:
Content-Signal jest obecny:
Content-Signal: ai-train=yes, search=yes, ai-input=yesContent-Signal jest wewnątrz bloku User-agent — nie przed nim. Jeśli jest przed pierwszym User-agent: — część parserów może zignorować cały plik.
Allow dla endpointu jest przed Disallow:
Allow: /wp-json/twoja-przestrzen/v1/slownik
Disallow: /wp-json/Kolejność ma znaczenie — pierwsza pasująca reguła wygrywa.
Sitemap jest wskazana:
Sitemap: https://twoja-strona.pl/sitemap_index.xmlKomenda 4: czy JSON endpoint jest dostępny dla agentów
curl -sI https://twoja-strona.pl/wp-json/twoja-przestrzen/v1/slownik | grep -E "content-type|x-robots"Oczekiwany wynik:
content-type: application/json; charset=UTF-8
x-robots-tag: index, followJeśli x-robots-tag: noindex: WordPress domyślnie dodaje noindex do wszystkich REST API responses. Musisz to nadpisać dla swojego endpointu — inaczej część agentów i crawlerów odmówi przetworzenia odpowiedzi mimo że technicznie jest dostępna.
Jeśli HTTP 404: endpoint nie istnieje lub nie jest zarejestrowany. Sprawdź czy kod rejestracji endpointu jest aktywny i odśwież permalinki (WP Admin → Ustawienia → Bezpośrednie odnośniki → Zapisz).
Jeśli HTTP 403: endpoint istnieje ale wymaga autentykacji. Sprawdź permission_callback w rejestracji — dla publicznego endpointu powinno być '__return_true'.
Możesz też sprawdzić czy dane są poprawne:
curl -s https://twoja-strona.pl/wp-json/twoja-przestrzen/v1/slownik | python3 -m json.tool | head -30Powinieneś zobaczyć sformatowany JSON z pierwszymi pojęciami.
Komenda 5: pełny test w jednej chwili
Zamiast wykonywać komendy jedna po drugiej — możesz uruchomić wszystko naraz:
SITE="https://twoja-strona.pl"
echo ""
echo "━━━ 1. service-doc header ━━━"
curl -sI $SITE/ | grep -i link
echo ""
echo "━━━ 2a. Markdown — agent ━━━"
curl -sI $SITE/ -H "Accept: text/markdown" | grep content-type
echo ""
echo "━━━ 2b. HTML — przeglądarka ━━━"
curl -sI $SITE/ | grep content-type
echo ""
echo "━━━ 3. robots.txt ━━━"
curl -s $SITE/robots.txt | grep -E "Content-Signal|Allow|Disallow" | head -6
echo ""
echo "━━━ 4. JSON endpoint ━━━"
curl -sI $SITE/wp-json/twoja-przestrzen/v1/slownik | grep -E "content-type|x-robots"Zamień twoja-strona.pl i twoja-przestrzen na właściwe wartości, wklej do terminala i masz pełny raport agent-readiness w kilka sekund.
Co robi Cloudflare checker inaczej
Narzędzie Cloudflare na isitagentready.com robi w zasadzie to samo co komendy powyżej — tylko z ładnym interfejsem i konkretnym scoringiem.
Różnica jest jedna: checker testuje z adresów IP Cloudflare. Jeśli masz reguły bezpieczeństwa które blokują datacenter IP — checker może nie dostać odpowiedzi mimo że strona działa dla normalnych użytkowników.
Jeśli Twoje curl testy pokazują wszystko zielone a checker nadal zgłasza problemy — sprawdź reguły WAF w Cloudflare czy nie blokujesz ich własnych botów.
Tabela szybkiej diagnozy
| Co testujesz | Komenda | Oczekiwany wynik |
|---|---|---|
| service-doc | curl -sI SITE/ | grep -i link |
link: </dla-agentow>; rel="service-doc" |
| Markdown agent | curl -sI SITE/artykul/ -H "Accept: text/markdown" | grep content-type |
text/markdown |
| HTML przeglądarka | curl -sI SITE/ | grep content-type |
text/html |
| Content Signals | curl -s SITE/robots.txt | grep Content-Signal |
ai-train=yes, search=yes, ai-input=yes |
| JSON endpoint | curl -sI SITE/wp-json/... | grep x-robots |
index, follow |
Nie chcesz robić tego ręcznie?
Plugin Agent-Ready WP dostępny wkrótce na iFox.pl ma wbudowany panel diagnostyczny który robi dokładnie to co komendy powyżej — tyle że z poziomu WP Admin, bez terminala, z kolorowym wskaźnikiem co działa a co wymaga uwagi.
Dla osób które wolą nie grzebać w curl i functions.php — to jest najszybsza droga do agent-readiness na WordPress.
Podsumowanie serii
Przez sześć artykułów przeszliśmy przez kompletne wdrożenie agent-readiness na WordPress:
Artykuł 1 — czym jest agent-readiness i dlaczego większość stron WordPress startuje z 0/100
Artykuł 2 — rel="service-doc", strona /dla-agentow i pułapka LiteSpeed cache
Artykuł 3 — Markdown for Agents bez Cloudflare Pro i krytyczna pułapka z Vary: Accept
Artykuł 4 — Content Signals w robots.txt i dlaczego kolejność dyrektyw ma znaczenie
Artykuł 5 — JSON API z WordPress CPT i dwa domyślne błędy REST API
Artykuł 6 — diagnostyka przez curl, pełny raport w jednej chwili
Wynik końcowy: Discoverability 100, Content 100, Bot Access Control 100 — bez Cloudflare Pro, bez VPS, na współdzielonym hostingu.
Wszystkie wdrożenia opisane w serii działają dziś na webflux.pl. Kod, pułapki i rozwiązania — z pierwszej ręki, nie z dokumentacji.
Ten artykuł jest częścią serii „WordPress Agent-Readiness”. Wszystkie wdrożenia zostały przetestowane na webflux.pl — włącznie z błędami i ich naprawą.