")
Gotowość polskich stron na erę agentów AI
Sprawdziłem 200 polskich stron branżowych pod kątem gotowości na agentów AI. 165 odpowiedziało. Żadna nie spełnia pełnych kryteriów AI-readiness.
To jest raport z tego badania.
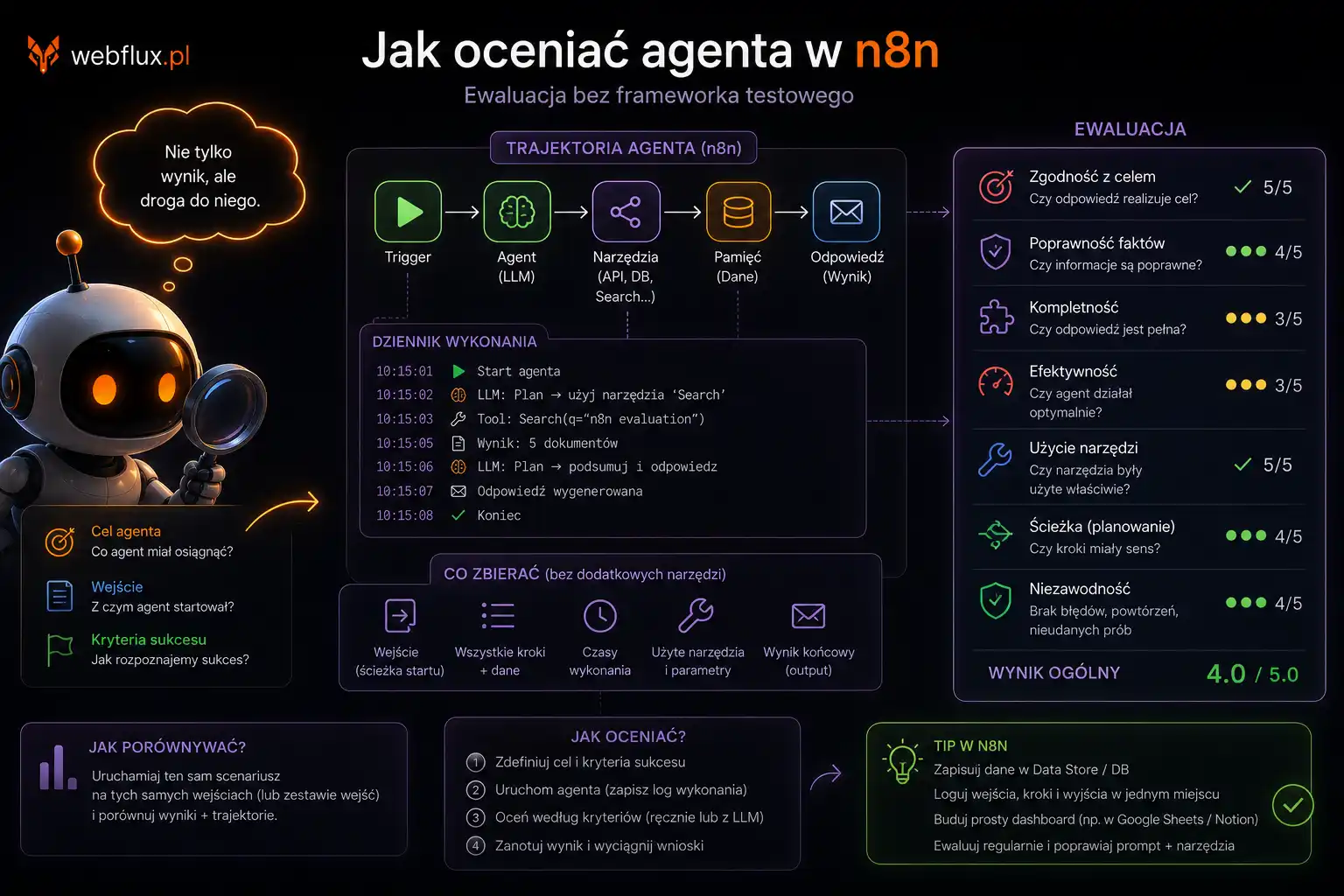
Co sprawdzałem i jak
Agent crawlujący odwiedził każdą domenę bez renderowania JavaScript — tak jak robi to agent AI, który dostał zadanie znaleźć produkt, zamówić usługę albo odpowiedzieć na pytanie użytkownika. Nie oceniałem wyglądu, szybkości marketingowej ani pozycji w Google. Oceniałem to, czy strona jest czytelna dla maszyny, która nie klika.
33 kryteria techniczne, 6 filarów, maksymalnie 100 punktów. Filar 1 to czytelność HTML bez JavaScript. Filar 2 to dane strukturalne — schema.org, JSON-LD. Filar 3 to odkrywalność dla agentów — robots.txt, llms.txt, Content Signals. Filar 4 to operacyjność — czy agent może coś zrobić na stronie, nie tylko ją przeczytać. Filar 5 to tożsamość — czy strona mówi, kim jest, w sposób zrozumiały maszynowo. Filar 6 to governance — świadoma polityka wobec agentów AI.
Pełna metodologia jest opublikowana osobno. Tu interesują mnie wyniki.
Obraz ogólny: polska sieć w połowie drogi
Średni wynik: 47,5 na 100.
To jest punkt na skali między „strona jest technicznie poprawna” a „strona jest gotowa na agentów AI”. Polskie strony branżowe mają solidną warstwę techniczną — HTTPS, robots.txt, podstawowe schema.org — ale brakuje im tej drugiej, wyższej warstwy, którą agenty AI potrzebują, żeby działać skutecznie.
Rozkład wyników mówi to samo precyzyjniej:
| Kategoria | Próg | Liczba stron | Udział |
|---|---|---|---|
| AI-Ready | 85–100 | 0 | 0% |
| Zaawansowana | 70–84 | 2 | 1% |
| W trakcie | 50–69 | 74 | 45% |
| Początkująca | 30–49 | 72 | 44% |
| Niewidoczna | 0–29 | 17 | 10% |
Nikt nie dobrnął do kategorii AI-Ready. Dwie strony znalazły się w kategorii Zaawansowana — synerise.com i ifirma.pl, obie z wynikiem 72/100. Dzieli je od progu AI-Ready 13 punktów. Reszta próby — 89% stron — mieści się między „zaczyna” a „jest w trakcie”.
Nie ma powodu, żeby ten obraz zaskakiwał. Agent-readiness to temat, który w polskim rynku pojawił się poważnie najwcześniej pod koniec 2024 roku. Standardy wciąż dojrzewają. Wdrożenia są nieliczne. Liczba 47,5/100 jest realistyczna.
Co już działa
Trzy wskaźniki, które wyglądają dobrze.
HTTPS: 100%. Wszystkie 165 stron które odpowiedziały serwują treść przez HTTPS. To jest dziś standard infrastrukturalny, nie element agent-readiness — ale jego brak byłby sygnałem ostrzegawczym. Jego pełna obecność w próbie potwierdza, że badamy strony z utrzymaną podstawową higieną techniczną.
robots.txt: 88%. 146 z 165 stron ma plik robots.txt. To jest istotne — robots.txt jest punktem wejścia dla każdego agenta AI, który chce wiedzieć, czego mu wolno. Bez niego agent musi zgadywać albo stosować domyślny ostrożny preset. Wysoka obecność robots.txt to dobra wiadomość, ale sama obecność pliku nie wystarczy — liczy się jego zawartość.
Schema.org: 75%. Trzy czwarte badanych stron ma dane strukturalne. To jest wynik lepszy niż się spodziewałem, ale jest tu pułapka: obecność schema.org w HTML to nie to samo co poprawna, kompletna, aktualnie utrzymana schema.org. Agent który dostaje pustą organizację z samą nazwą albo produkt bez ceny i dostępności, dostaje dane strukturalne — ale nie dostaje nic użytecznego. Liczba 75% mówi, że warstwa istnieje. Nie mówi, co w niej jest.
Czego nie ma
Trzy wskaźniki, które mówią co innego.
llms.txt: 23%
38 z 165 stron ma plik llms.txt — markdownowy spis zawartości witryny przeznaczony dla modeli językowych.
Zanim ta liczba zabrzmi optymistycznie, jest do niej ważna adnotacja. Część serwerów zwraca HTTP 200 dla nieistniejących zasobów zamiast HTTP 404. Crawler traktuje HTTP 200 jako obecność pliku. W surowych danych llms.txt miało 28% stron — po usunięciu prawdopodobnych soft-404 (stron z niskim ogólnym wynikiem, gdzie obecność llms.txt była statystycznie nieprawdopodobna) liczba spada do 23%.
23% to wciąż zaskakująco dużo jak na maj 2026. Wśród stron z llms.txt dominują firmy technologiczne i SaaS — livechat.com, tidio.com, ifirma.pl, baselinker.pl, infakt.pl, pragmago.pl — gdzie kultura techniczna i dbałość o maszynową czytelność jest wyższa niż średnia rynkowa. W e-commerce llms.txt ma morele.net, taniaksiazka.pl, deichmann.pl, quiosque.pl. W mediach — wp.pl, spidersweb.pl, focus.pl, computerworld.pl.
Dla kontekstu: jeszcze rok temu llms.txt nie istniało w polskiej dyskusji technicznej. 23% — nawet z poprawką na soft-404 — to tempo adopcji, którego nie spodziewałem się zobaczyć w pierwszej edycji.
Content Signals: 2,4%
4 strony z 165 mają w robots.txt dyrektywę Content-Signal — mechanizm wprowadzony przez Cloudflare we wrześniu 2025, który pozwala zadeklarować politykę wobec AI: czy zgadzam się na indeksowanie, na używanie treści jako kontekstu dla odpowiedzi AI, na trening modeli.
Quiosque.pl, digitree.pl, seogroup.pl, computerworld.pl. To są pierwsze polskie strony, które powiedziały agentom AI wprost: tu jest moja polityka wobec was.
2,4% to tyle co nic — ale rok temu byłoby to 0%. I to nie jest ocena. To jest obserwacja o tempie i miejscu adopcji.
Branże: e-commerce ma największy problem
| Branża | Liczba stron | Średni wynik |
|---|---|---|
| Tech / B2B | 46 | 50,9 |
| Media | 49 | 47,8 |
| Agencje digital | 35 | 47,1 |
| E-commerce | 35 | 43,0 |
E-commerce wypada najsłabiej — i to jest wynik, który wymaga komentarza, bo jest paradoksem.
Agenty zakupowe — ChatGPT z Instant Checkout, Microsoft Copilot Checkout, agenty zakupowe wbudowane w asystentów na telefonach — działają dziś lub zaczną działać za kilka miesięcy. Ich główny use case to szukanie produktów, porównywanie cen i finalizowanie zakupów. Warstwa, na której będą działać, to polskie sklepy internetowe. Te same sklepy, które w tym badaniu wypadły najsłabiej.
Średni wynik 43 punkty w kategorii e-commerce oznacza, że agent zakupowy, który trafi na przeciętny polski sklep, nie znajdzie poprawnych danych produktowych w schema.org, prawdopodobnie nie trafi na llms.txt, i nie będzie wiedział, jaka jest polityka sklepu wobec agentów AI. Będzie musiał zgadywać albo odpuścić.
Agencje digital z wynikiem 47,1 to osobna obserwacja. Firmy, które doradzają klientom w sprawach cyfrowej widoczności, same nie wdrożyły standardów, o których coraz częściej piszą. To nie jest zarzut — to jest stan rynku w maju 2026, gdzie wdrożenia dopiero zaczynają wyprzedzać dyskusję.
Tech i B2B na 50,9 wynika z prostego faktu: firmy SaaS mają kulturę techniczną i dbają o maszynową czytelność produktu z powodów niezwiązanych bezpośrednio z agent-readiness — dokumentacja API, JSON-LD na stronach produktowych, REST API. Efektem ubocznym jest wyższy wynik w badaniu.
Wielkie marki, które nie odpowiedziały
35 domen w próbie nie zwróciło danych — agent nie był w stanie pobrać strony głównej. Wśród nich jest siedem marek, których obecność lub nieobecność w wynikach jest sama w sobie informacją:
allegro.pl, x-kom.pl, castorama.pl, leroy-merlin.pl, decathlon.pl, notino.pl, obi.pl.
To są największe polskie lub działające w Polsce sklepy internetowe, z infrastrukturą chroniącą przez Cloudflare WAF lub podobne rozwiązania. Nie zablokował ich żaden błąd w konfiguracji — zablokował je aktywny wybór: nie wpuszczamy zewnętrznych crawlerów.
Ten wybór ma konsekwencję, którą warto nazwać wprost. Agent który nie może pobrać robots.txt i strony głównej, nie może ocenić, czego mu wolno. Nie może odczytać danych produktowych. Nie może sprawdzić, czy checkout jest dostępny bez JavaScript. Może albo nie obsłużyć zapytania użytkownika, albo obsłużyć je na podstawie starych danych z treningu. Blokada crawlerów AI-readiness i blokada agentów AI to — z technicznego punktu widzenia — często ta sama decyzja.
Nie oznacza to, że wielkie marki podjęły złą decyzję. Może chronią się przed scrapingiem, nadużyciami, inżynierią konkurencji. Ale efektem ubocznym jest niewidoczność dla agentów działających w imieniu klientów. To jest trade-off, który za rok lub dwa będzie miał wymierną cenę.
Ceneo: cross-walidacja z Cloudflare
Najniższy wynik wśród rozpoznawalnych marek, które odpowiedziały, to ceneo.pl: 22 punkty.
Ceneo jest największym polskim serwisem porównywania cen. W erze agentów zakupowych to jest naturalna brama — agent który ma znaleźć dla użytkownika najlepszą ofertę w Polsce, powinien zacząć od Ceneo. 22/100 oznacza, że ta brama jest dla agenta prawie nieprzejrzysta.
Dla weryfikacji sprawdziłem Ceneo w Cloudflare „Is Your Site Agent-Ready?” — niezależnym narzędziu mierzącym readiness z perspektywy warstwy protokołowej. Wynik Cloudflare: 17 punktów.
Dwa niezależne narzędzia, różne metodologie, zbieżna diagnoza. iFox mierzy warstwę treściową: dane strukturalne, llms.txt, Content Signals, semantykę HTML. Cloudflare mierzy warstwę protokołową: nagłówki HTTP, content negotiation, deklaracje w robots.txt. Oba wskazują na ten sam problem.
Wynik 22 czy 17 — niezależnie od narzędzia — oznacza to samo: strona, która powinna być najgotowszym miejscem na polskim internecie dla agentów zakupowych, nie jest gotowa.
Ograniczenia tego badania
Raport mierzy obecność i poprawność składniową elementów technicznych. Nie ocenia ich skuteczności.
Schema.org która jest obecna, ale opisuje produkt bez ceny — spełnia kryterium obecności, nie spełnia kryterium użyteczności. llms.txt który ma 30 słów i jedną linię z tytułem strony — spełnia kryterium obecności, nie spełnia kryterium wartości. Agent który dostanie takie dane — dostanie dane, ale nie dostanie nic, na czym mógłby polegać.
Badanie nie sprawdzało warstwy operacyjnej dla każdego typu strony z osobna — czy agent może rzeczywiście sfinalizować zakup, wysłać formularz, odczytać aktualny stan zamówienia. To wymaga ręcznych testów, nie automatycznego crawlu. Ta warstwa jest dla badania niedostępna.
35 domen pominięto. Wśród nich są największe marki w próbie. Ich wyniki są nieznane.
Te ograniczenia są częścią metodologii, nie jej ukrytymi wadami. Raport mierzy to, co można zmierzyć automatycznie i powtarzalnie. Mierzy to samo w każdej edycji — co pozwala śledzić zmiany w czasie.
Co z tego wynika
Sześć konkretnych obserwacji z danych.
Pierwsza. Nikt nie jest AI-Ready. Max 72/100 przy progu 85. Jeśli pojawi się agent który zaczyna podejmować decyzje zakupowe, medialne albo B2B w oparciu o polskie strony — zrobi to na danych niekompletnych.
Druga. Podstawy są. HTTPS 100%, robots.txt 88%, schema.org 75%. Polska sieć ma techniczną warstwę, na której można budować. Brakuje warstwy wyższej.
Trzecia. llms.txt rośnie szybciej niż myślałem. 23% to dużo jak na pierwszy rok. Większość z tych wdrożeń jest w branży tech — ale jest.
Czwarta. Content Signals jest praktycznie nieobecne. 4 strony z 165. To jest deklaracja polityki treści wobec AI. Jej brak nie jest złą wiadomością — jest brakiem decyzji. Część firm zdecyduje na tak, część na nie, a część świadomie zostawi pytanie otwarte. Dziś prawie nikt nie podjął tej decyzji.
Piąta. E-commerce jest najsłabszy tam, gdzie stawka jest najwyższa. Agenty zakupowe nie są fikcją — są wdrożeniem w ChatGPT, Copilot, asystentach Google. Polskie sklepy nie są na nie gotowe.
Szósta. Wielkie marki blokują. Allegro, decathlon, castorama — nie odpowiedziały. To jest wybór, który ma koszt, który jeszcze nie jest widoczny w żadnym raporcie analitycznym.
Następna edycja pokaże, co się zmieniło.
Sprawdź wynik swojej domeny: ifox.pl/geo-checker/
Metodologia badania: webflux.pl/raport-ai-readiness-2026/metodologia/
PDF do pobrania: Raport