Latem 2024 Cloudflare ogłosił pay-per-crawl — funkcję, która miała pozwolić wydawcom zażądać mikropłatności od AI-crawlerów za każde pobranie treści. Komunikat brzmiał czysto i atrakcyjnie: w erze, w której modele AI pobierają twoje teksty bez wzajemności, ty wreszcie odzyskujesz kontrolę. Ustawiasz cenę. Crawler płaci albo odchodzi. Mikroprzychody zaczynają płynąć.
Półtora roku później, w kwietniu 2026, polski internet wciąż referuje pay-per-crawl jako jedno z głównych narzędzi monetyzacji ruchu agentowego. Konsultanci agencyjni wpisują to do prezentacji dla klientów. Branżowe portale wymieniają jako „nową rzeczywistość mediów”. Konferencje robią z tego panele dyskusyjne.
W tym samym czasie liczba polskich stron, które faktycznie zarabiają na pay-per-crawl, jest bliska zeru. I nie dlatego, że nikt go nie wdrożył. Dlatego, że ekonomia tego rozwiązania na razie się nie domyka — a większość tekstów branżowych po prostu pomija ten szczegół.
Ten wpis jest pierwszym z pięciu w serii „Czego nie wdrożycie w 2026 — agentic web między hype a produkcją”. W każdym wezmę jedno głośno reklamowane rozwiązanie i pokażę, dlaczego inwestycja w nie dziś jest inwestycją w niewiadomą — oraz co warto zrobić zamiast.
Co reklamują
Komunikat Cloudflare przy uruchomieniu funkcji w lipcu 2025 mówił trzy rzeczy. Pierwsza — wydawca ustala cenę za pobranie zasobu przez bota AI. Druga — Cloudflare obsługuje rozliczenie, więc wydawca nie musi budować własnej infrastruktury płatniczej. Trzecia — bot albo akceptuje cenę i płaci, albo nie ma dostępu do treści. Mechanizm prosty, mechanizm sprawiedliwy, mechanizm działający.
Wokół tego komunikatu narosła branżowa narracja. „Wydawcy odzyskują głos w sporze z AI-crawlerami”. „Nowa era monetyzacji treści”. „Mikropłatności wreszcie znajdują zastosowanie, na które czekały od dekady”. Te zdania pojawiają się w polskich i zagranicznych publikacjach branżowych z taką częstotliwością, że łatwo wziąć je za odzwierciedlenie rzeczywistego stanu rynku.
Do tego dochodzi rosnąca liczba podobnych ofert. TollBit jako platforma agregująca treści mniejszych wydawców. ScalePost. Kilka mniejszych projektów na różnych rynkach. Każda nowa platforma wzmacnia wrażenie, że pay-per-crawl to ekosystem, który dojrzewa. Każda nowa wzmianka w mediach branżowych utrwala wrażenie, że tylko spóźnialscy nie wdrażają.
Brzmi jak coś, w co warto wejść.
Co naprawdę jest
Trzy rzeczy, których w tej narracji brakuje.
Po pierwsze — adopcja po stronie crawlerów. Pay-per-crawl działa tylko wtedy, kiedy bot AI zgadza się płacić. To znaczy — jego operator musi mieć podpisaną umowę z Cloudflare, mieć aktywne konto rozliczeniowe i zaakceptować cenę, którą ustawił wydawca. W praktyce w kwietniu 2026 większość crawlerów, które pobierają treści w skali, nie ma takiej integracji. Wybór, który dostają, brzmi: zapłać albo odejdź. Większość odchodzi. Bo dla operatora crawlera, który pobiera dziennie miliony stron, integracja z systemem mikropłatności jednego dostawcy CDN jest kosztownym overheadem, którego unika się dopóki to możliwe.
To znaczy, że twoja strona z włączonym pay-per-crawl nie zarabia na crawlerach — ona ich traci. To może być dokładnie efekt, którego chcesz (jeśli twoja polityka brzmi „nie chcę być w danych treningowych modeli”). Ale to nie jest „monetyzacja” w klasycznym sensie. To jest blokada z rachunkiem na zero złotych.
Po drugie — ekonomia per pobranie. Mikropłatności w pay-per-crawl są bardzo mikro. Cloudflare nie publikuje rekomendowanych stawek, ale rynkowe wartości oscylują w okolicach kilku-kilkudziesięciu setnych grosza za pobranie zasobu. Dla wydawcy, który ma miesięcznie pięćdziesiąt tysięcy wizyt botów AI, to przychód rzędu kilkunastu-kilkudziesięciu złotych miesięcznie. Nawet jeśli wszystkie boty by zapłaciły. A nie zapłacą.
Realna ekonomika domyka się tylko dla wielkich wydawców z setkami tysięcy albo milionami pobrań miesięcznie. New York Times, Reuters, Axel Springer mają sens biznesowy w pay-per-crawl. Polski blog branżowy z dwoma tysiącami botowych wizyt miesięcznie ma w pay-per-crawl symbolikę, nie przychód.
Po trzecie — alternatywne ścieżki, które już działają. Duzi wydawcy nie czekają na pay-per-crawl. OpenAI w ostatnich kwartałach podpisało umowy licencyjne z Associated Press, Axel Springer, Dotdash Meredith, Vox Media, News Corp. Anthropic zrobił podobne kroki. Te umowy są sumami siedmio- i ośmiocyfrowymi rocznie, negocjowane indywidualnie, niedostępne dla mniejszych graczy. Ale dla tych, którzy mają z czym negocjować, są realnym strumieniem przychodów już dziś — w przeciwieństwie do pay-per-crawl, który dopiero ma się rozwinąć.
Dla mniejszych wydawców powstają platformy pośredniczące — TollBit, ScalePost — które agregują treści wielu mniejszych podmiotów i negocjują zbiorczo. To też nie jest pay-per-crawl. To jest klasyczne licencjonowanie, tylko zorganizowane tak, żeby próg wejścia był niższy. Dziś to ma większy sens ekonomiczny niż czekanie aż infrastruktura mikropłatności dojrzeje.
Pisałem o tym szerzej w wpisie z serii Agent-ready o filarze szóstym agent-readiness — tam rozkładam całą logikę monetyzacji ruchu agentowego, której pay-per-crawl jest tylko jedną z kilku ścieżek.
Dlaczego to nie znaczy, że pay-per-crawl nie wypali
Krytyka, którą tu prowadzę, nie jest pochopnym przekreśleniem całego pomysłu. Pay-per-crawl jako kierunek ma sens strukturalny. Mikropłatności od bota są elegantnym rozwiązaniem problemu, który dziś rozwiązuje się siłą — albo licencjonowaniem dla wielkich, albo blokadą dla małych. Jeśli infrastruktura dojrzeje, jeśli operatorzy dużych modeli AI zintegrują się z systemami mikropłatności, jeśli stawki wzrosną do poziomu, w którym ekonomika domyka się dla mniejszych wydawców — pay-per-crawl może stać się standardem.
Trzy warunki, które muszą się spełnić.
Pierwszy — masowa adopcja po stronie operatorów crawlerów. Dziś to wąskie gardło. Bez OpenAI, Anthropica, Google’a, Perplexity, Mety w systemie pay-per-crawl, mechanizm pozostaje niszowy.
Drugi — standardyzacja protokołów płatności. Dziś każdy dostawca CDN, który próbuje robić mikropłatności od botów (Cloudflare, próby na Akamai), ma własny standard. Crawlery, które miałyby się integrować z dziesiątką różnych systemów, integrują się z zerem.
Trzeci — wzrost stawek. Stawki dziś są tak niskie, że nawet wydawcy, którzy mogliby zarabiać, nie traktują tego jako realnego strumienia przychodu. To może się zmienić, kiedy wartość treningowa konkretnych treści wzrośnie — albo kiedy wzrośnie konkurencja między dostawcami modeli o wysokiej jakości dane.
W którym roku te trzy warunki się spełnią — tego nie wiem. Może w 2027. Może nigdy. Branża technologiczna ma w pamięci wiele rozwiązań, które wyglądały jak nieuchronność, a okazały się odejściem (vide WebMCP i poprzednie próby standaryzacji warstw między agentami a stronami).
Co zamiast tego zrobić w 2026
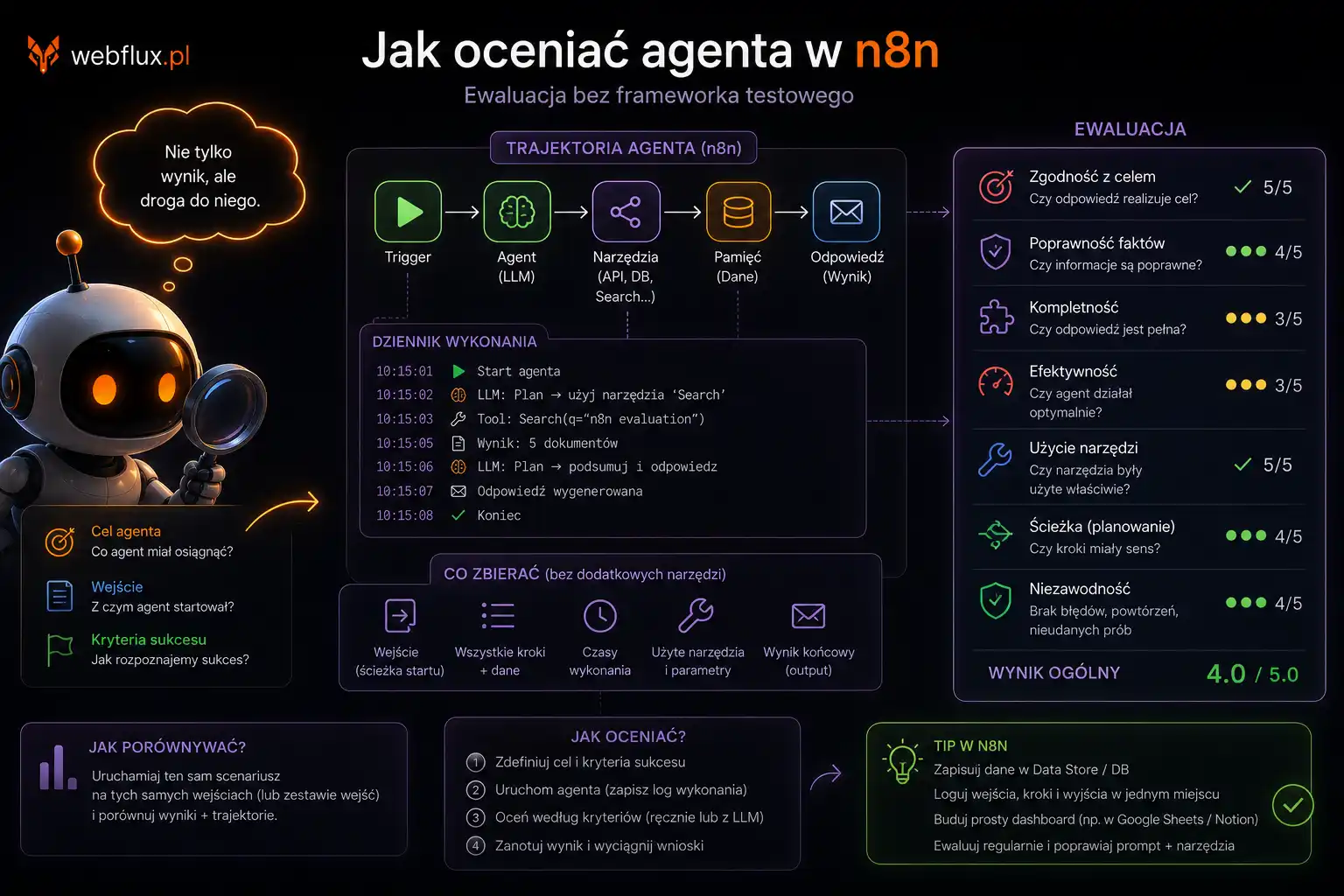
Zamiast inwestować w pay-per-crawl jako kanał monetyzacji, w 2026 warto zrobić trzy konkretne rzeczy. Wszystkie trzy są tańsze, szybsze i mają wyższą szansę zwrotu.
Po pierwsze — świadoma polityka w robots.txt. Jeśli nie chcesz, żeby twoje treści zasilały trening modeli AI, zablokuj boty treningowe (GPTBot, ClaudeBot, Google-Extended, Bytespider) wprost. To jest godzina pracy, zero kosztu, natychmiastowy efekt. Jeśli akceptujesz trening, ale chcesz monitorować ruch — zostaw je dopuszczone, ale uruchom monitoring w panelu Cloudflare albo w logach serwera. Bez świadomej polityki na warstwie sygnałów cała rozmowa o monetyzacji jest abstrakcją.
Po drugie — segmentacja ruchu agentowego. ChatGPT-User, Claude-User, PerplexityBot w trybie on-demand to nie jest ten sam ruch co GPTBot. Pierwsza grupa może przyprowadzić użytkownika z intencją zakupową albo cytować twoją stronę w odpowiedzi. Druga tylko trenuje model. Polityka per segment ma sens biznesowy, polityka „blokuj wszystko AI” zazwyczaj nie. Pisałem o tym konkretnie w wpisie o praktyce filaru 6.
Po trzecie — jeśli masz skalę i wartościowe treści, sprawdź licencjonowanie zbiorcze. TollBit, ScalePost i analogiczne platformy pośredniczące zaczynają działać dla mniejszych wydawców. Próg wejścia jest niższy niż negocjacje bezpośrednie z OpenAI, ale nadal wymaga pewnej masy treści. Dla bloga z setką wpisów to nie zadziała. Dla portalu branżowego z tysiącami artykułów eksperckich — może mieć sens.
Czego nie warto robić w 2026: traktować pay-per-crawl jako linię w biznesplanie. Włączyć go „bo wszyscy o nim piszą”. Inwestować czas w optymalizację stawek, których nikt nie zapłaci. Każda z tych decyzji to czas, który mógłbyś poświęcić na rzeczy, które już działają.
Z perspektywy bezpieczeństwa warstwa kontroli ruchu agentowego ma jeszcze jeden wymiar — to, kto faktycznie odwiedza twoją stronę i czy nie ukrywa się pod cudzym user-agentem. Pisałem o tym z perspektywy ataków na agenty na CyberFluxie, w wpisie „Agent nie odwiedza już tylko webu. Web zaczyna atakować agenta”. Polityka wobec ruchu agentowego nie jest dziś tylko kwestią monetyzacji — jest też kwestią tego, kto na twojej stronie naprawdę działa.
Kiedy wrócić do tematu
Pay-per-crawl warto sprawdzić ponownie w trzech momentach.
Pierwszy — kiedy Cloudflare opublikuje liczby. Dziś nie wiemy, ile stron faktycznie zarabia na pay-per-crawl, ile crawlerów się integruje, jakie są realne stawki. Bez tych danych każda dyskusja o ekonomii jest spekulacją. Cloudflare, który ma te dane, na razie ich nie udostępnia. Kiedy zacznie — będzie to sygnał, że rynek dojrzewa.
Drugi — kiedy któryś z dużych operatorów AI publicznie ogłosi integrację. OpenAI, Anthropic albo Google dołączający do systemu mikropłatności od crawlerów to byłby sygnał krytycznej masy. Dziś żadne z nich nie zrobiło tego ruchu, mimo półtora roku istnienia funkcji.
Trzeci — kiedy w Polsce pojawi się pierwszy wydawca, który publicznie pochwali się przychodem z pay-per-crawl. Nie wzmianką o włączeniu funkcji. Nie deklaracją, że „testuje”. Konkretną liczbą za miesiąc albo kwartał. Dziś takich case studies nie ma. Kiedy się pojawią, będzie znak, że ekonomia zaczyna się domykać.
Do tego momentu — pay-per-crawl jest funkcją, która istnieje. Nie jest jeszcze monetyzacją.