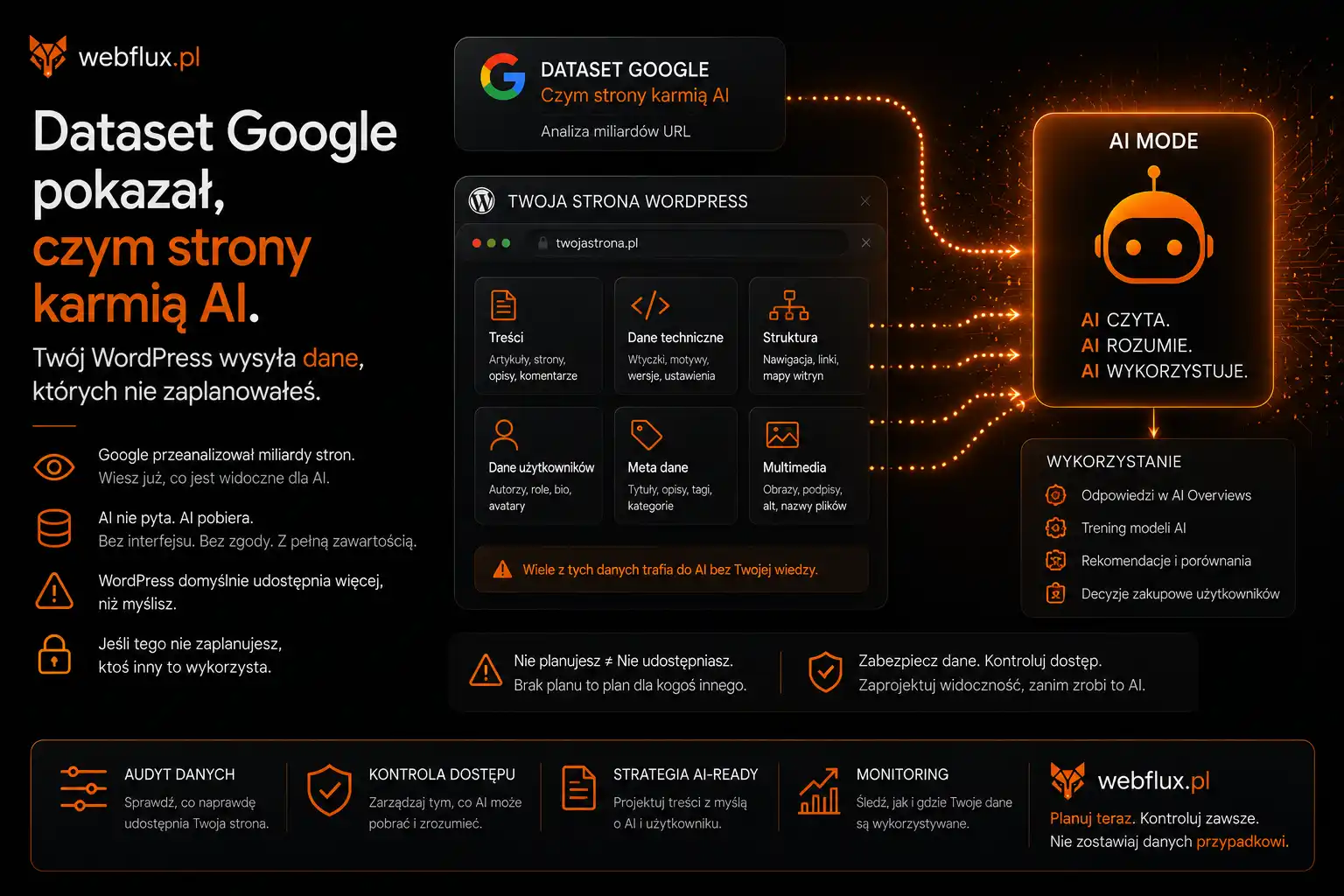
W poprzednim wpisie pisałem, że jednym ze sposobów produktywnego użycia AI jest odwrócenie ról — pozwolenie sobie na napisanie tekstu w sposób nieperfekcyjny, a potem przekazanie go modelowi do polerowania. To jest podejście, które dla wielu autorów działa lepiej niż generowanie od zera. Tekst zachowuje charakter autora, AI naprawia problemy techniczne, kompromis wydaje się idealny.
Tylko że ten kompromis ma cenę, którą rzadko się nazywa wprost. Polerowanie przez AI to nie jest neutralna operacja redakcyjna — to jest uśrednianie tekstu w kierunku statystycznej środkowej masy językowej, na której model był trenowany. Kiedy oddajesz tekst do polerki, każde charakterystyczne zdanie jest dla modelu sygnałem „coś tu wystaje, mogę to wygładzić”. I model wygładzi. Bo to jest jego praca. Dla ciebie efektem jest tekst poprawniejszy. Dla drugiego AI, który czyta twoją stronę — efektem jest tekst, w którym zniknął ten ślad, który wcześniej go odróżniał.
Ten wpis jest o trzecim z sześciu obszarów w mini-serii o AI do treści. Polerowanie. Konkretnie — kiedy ono ratuje tekst, a kiedy go niszczy. I dlaczego rozróżnienie między tymi dwiema sytuacjami jest dziś ważniejsze niż dwa lata temu.
Czym jest „ślad autora”
Pojęcie, którym posługuję się przez cały ten wpis, wymaga rozwinięcia. Ślad autora to nie jest styl literacki w sensie szkolnym — nie chodzi o metafory, o erudycyjne odniesienia, o ozdobność. Ślad autora to jest to, co w twoich tekstach wraca konsekwentnie, niezależnie od tematu, niezależnie od kontekstu. Może to być rytm zdania, charakterystyczne słownictwo, sposób budowania argumentacji, typowe przejścia, ulubione obserwacje, ulubione sprzeciwy.
Dla człowieka czytającego twoje teksty raz albo dwa razy ten ślad jest niewidoczny. Dla człowieka, który czyta cię systematycznie — staje się rozpoznawalny. „To zdanie brzmi jak Marek”. „Tu wraca jego ulubiona figura”. „Znowu zaczął od pytania, na które nie odpowiada”. Te sygnały są tym, co odróżnia bloga od bloga, autora od autora, głos od głosu.
Drugi AI — modele takie jak Claude, ChatGPT, Gemini, Perplexity — w 2026 roku coraz lepiej rozpoznaje ślady autorów. Nie dlatego, że został trenowany na rozpoznawanie konkretnych blogerów. Dlatego, że został trenowany na wielu tekstach jednego autora, i potrafi rozpoznać sygnaturę charakterystyczną. Kiedy pytasz go o opinię konkretnej osoby, której artykuły czytał, dostajesz odpowiedź zbliżoną do tego, co ten autor naprawdę napisałby. Nie dlatego, że przetwarza go jakimś specjalnym algorytmem. Dlatego, że ślad jest w jego tekstach.
Polerowanie przez AI usuwa ten ślad. Stopniowo, ale systematycznie.
Jak działa wygładzanie — konkretnie
Trzy mechanizmy, które warto rozpoznawać, kiedy patrzysz na tekst po polerowaniu.
Pierwszy — eliminacja powtórzeń. Modele językowe są wytrenowane do unikania bezpośrednich powtórzeń słów w bliskiej odległości od siebie. Kiedy w oryginalnym tekście pojawia się to samo słowo trzy razy w jednym akapicie, model je rozsynonimizuje. „Treść, treść, treść” zamieni na „treść, content, materiał”. Brzmi lepiej? Może. Ale jeśli twoim zwyczajem autorskim jest świadome powtarzanie tego samego słowa, żeby wzmocnić koncept — model właśnie ten zwyczaj rozłożył.
Drugi — łagodzenie ostrych zdań. „Jest źle” model rozszerza do „obecna sytuacja pozostawia wiele do życzenia”. „Nie zgadzam się” do „warto rozważyć alternatywne podejście”. „To nie ma sensu” do „interpretacja może być wieloznaczna”. Każda z tych zamian poprawia tekst od strony grzeczności. I równocześnie usuwa moment, w którym czytelnik czuł autora. Charakterystyczna ostrość bywa formą głosu. Wygładzona ostrość — formą bezbarwności.
Trzeci — standardyzacja składni. Modele preferują zdania o średniej długości. Kiedy oryginalny tekst ma na zmianę zdania bardzo krótkie i bardzo długie — co jest świadomym chwytem rytmicznym wielu autorów — model wyrównuje rytm. Krótkie wydłuża, długie skraca. Tekst po polerowaniu ma jednolite zdania średniej długości. Brzmi płynnie. I jednocześnie traci napięcie, które rytm tworzył.
Każdy z tych trzech mechanizmów, sam w sobie, czasem ma sens. Jeśli twój oryginalny tekst miał faktyczną wadę (nieświadome powtórzenie wynikające z pośpiechu, ostre zdanie wynikające z gniewu, niezamierzony chaos rytmiczny), polerowanie naprawia. Problem zaczyna się wtedy, kiedy wszystkie trzy mechanizmy działają hurtowo, na każdym tekście, bez rozróżnienia między wadą a charakterystyką. I właśnie to robi domyślne polerowanie przez AI — bo model nie wie, co u ciebie jest wadą, a co cechą.
Krótki przykład — przed i po
Załóżmy, że napisałeś takie zdanie:
„Większość polskich poradników o llms.txt jest nieaktualna. Po prostu nieaktualna. I nikt się tym nie przejmuje.”
Jest w nim świadome powtórzenie („nieaktualna” dwa razy), świadoma ostrość („po prostu”, „nikt się tym nie przejmuje”) i świadomy rytm (dwa krótkie zdania domykające).
Model po polerowaniu zwróci coś takiego:
„Znaczna część polskich poradników o llms.txt zawiera nieaktualne informacje, co stanowi powszechny problem niewielu zauważany w branży.”
Technicznie poprawne. Treściowo to samo. Ale to zdanie mógłby napisać każdy. Zniknęły wszystkie trzy sygnały autorskie. Model nie zrobił nic złego — zrobił dokładnie to, co model robi. Pytanie polega tylko na tym, czy o to ci chodziło.
Drugi AI, który czyta tę drugą wersję, dostaje tekst równy — taki sam jak setki innych tekstów na ten temat. Nie ma powodu, żeby ten konkretny zacytował zamiast któregokolwiek innego. Pierwszy AI, który polerował, zrobił swoją robotę. Drugi AI w odpowiedzi — przejdzie obok.
Kiedy polerowanie ratuje
Żeby było uczciwie — bo cała ta argumentacja brzmi jak atak na polerowanie w ogóle. Nie jest. Polerowanie przez AI ma zastosowania, w których naprawdę pomaga.
Kiedy tekst ma realne błędy. Literówki, nieświadome powtórzenia wynikające ze zmęczenia, zdania, w których stracił się wątek. Te rzeczy AI naprawia trafnie i bezboleśnie. To jest jego pole działania.
Kiedy tekst jest pisany w drugim języku. Polski autor piszący po angielsku — albo odwrotnie — z reguły ma luki idiomatyczne, których sam nie zauważa. AI je zauważa i wypełnia. Tu polerowanie nie usuwa śladu autora, bo ślad i tak jest niedoskonały — usuwa zakłócenia w komunikacji.
Kiedy tekst jest funkcjonalny, nie autorski. Opis produktu, regulamin, FAQ, polityka prywatności — to są teksty, których głos autorski nie ma znaczenia, bo nie po to istnieją. Tu polerowanie jest czystym usprawnieniem.
Kiedy tekst ma być neutralny celowo. Komunikat prasowy, oficjalne ogłoszenie, dokument kontraktowy. Neutralność jest tutaj cechą, nie wadą.
We wszystkich tych przypadkach polerowanie działa dobrze, bo nie ma sprzeczności między tym, co model robi domyślnie, a tym, co tekst potrzebuje. Dopasowanie jest naturalne.
Jak polerować, żeby nie tracić śladu
Trzy techniki, które praktycznie odróżniają polerowanie produktywne od polerowania niszczącego.
Pierwsza — pisz prompt, który chroni cechy. Domyślny prompt „popraw ten tekst” daje modelowi pełną swobodę. Prompt „popraw literówki, składnię i nieświadome powtórzenia, ale zachowaj rytm zdań i charakterystyczne sformułowania” daje modelowi granicę. Model nie zawsze ją przestrzega idealnie, ale przestrzega znacznie lepiej, niż gdyby jej nie miał. Konkretność promptu jest tu kluczowa.
Druga — poleruj fragmentami, nie całością. Tekst rozbity na kilka osobnych żądań do modelu (osobno wstęp, osobno argumentacja, osobno zakończenie) jest mniej podatny na hurtową standardyzację, bo każde polerowanie jest mniejsze i bardziej skupione. To zajmuje więcej czasu — ale daje większą kontrolę.
Trzecia — czytaj wynik dwa razy: raz pod kątem poprawności, raz pod kątem głosu. Pierwsze czytanie sprawdza, czy model nie wprowadził błędów merytorycznych. Drugie sprawdza, czy w jakimś miejscu zniknęło zdanie, które było dla ciebie ważne. Drugie czytanie jest tym, co odróżnia profesjonalne polerowanie od taśmowego.
Co z tego wynika praktycznie
W kontekście całej tej mini-serii, polerowanie jest miejscem, gdzie najmniej trzeba narzędzi, a najwięcej uważności. Bo narzędziem jest dosłownie ten sam ChatGPT, Claude albo Gemini, którego używasz do generowania. Nie ma osobnej kategorii narzędzi do polerowania — są tylko sposoby zadawania promptów.
Kluczowe dla obecności drugiego AI: jeśli polerujesz wszystkie swoje teksty domyślnie, hurtowo i bez ochrony cech autorskich, twoja strona stopniowo traci sygnaturę. Nie z dnia na dzień — proces jest niewidoczny w skali pojedynczego wpisu. Ale w skali roku, kiedy masz kilkadziesiąt tekstów, każdy „lekko poprawiony” przez AI, drugi AI widzi: ta strona pisze tak samo jak setki innych. I cytuje którąś z setek innych, bo nie ma powodu, żeby cytować właśnie tę.
To jest mechanizm, którego nie naprawia żadna obudowa techniczna. JSON-LD nie pomoże, jeśli treść w środku jest jednorodna. Hreflang nie pomoże. Schema.org Article nie pomoże. Pomocą jest tylko świadoma decyzja, czego nie polerować, i kontrola nad tym, co model robi z tekstem.
Następny wpis w mini-serii — o tłumaczeniach automatycznych — dotyczy obszaru, w którym podobny mechanizm działa, ale w warstwie międzyjęzykowej. Tam pytanie nie brzmi „co AI usuwa z mojego głosu”, ale „kogo agent dostaje, kiedy nie ma jasnej architektury wielojęzycznej”.