Zaczynam od warstwy najprostszej do zrozumienia i najtrudniejszej do zaakceptowania w pełnym wymiarze.
Warstwa web — strony internetowe, blogi, dokumentacja, portale — jest najczęściej omawianą częścią agentic web w polskim rynku. To tu zaczęła się dyskusja o llms.txt, o robots.txt dla AI, o schema.org jako sygnale dla modeli językowych. To tu polskie agencje piszą artykuły o GEO i o tym, że „trzeba być gotowym na agentów AI”.
I to właśnie tu przepaść między tym, co się mówi, a tym, co jest wdrożone, jest największa.
W maju 2026 sprawdziłem 165 polskich stron branżowych. Wyniki opisałem w Polskim Raporcie AI-Readiness 2026. Jeden wniosek do zapamiętania: żadna strona w badanej próbie nie osiągnęła progu AI-Ready. Najwyższy wynik: 72/100. Próg AI-Ready zaczyna się od 85.
Warstwa web w Polsce jest dojrzała w dyskusji. Nie jest dojrzała w praktyce.
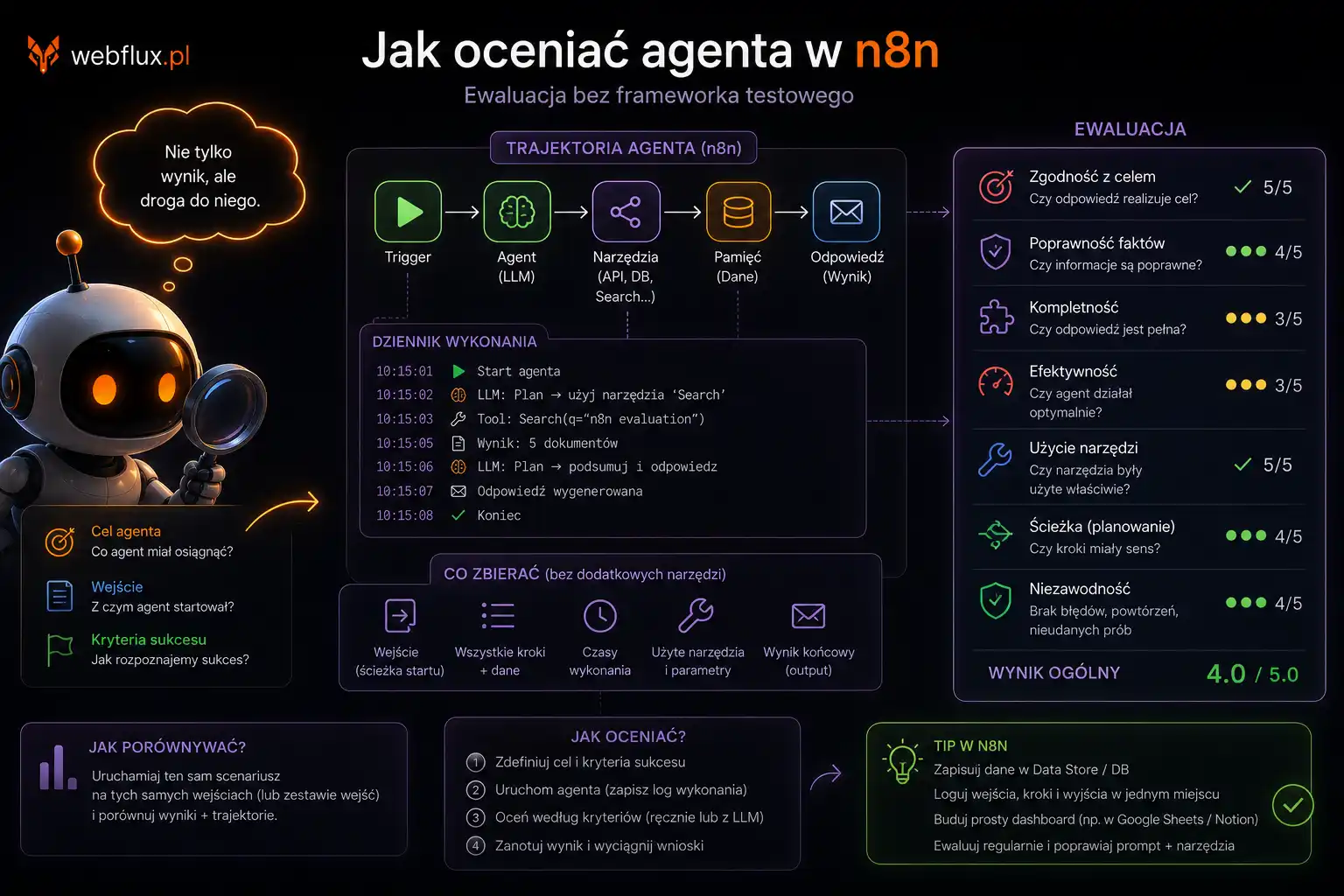
Co agent AI robi na Twojej stronie
Zanim powiem co jest do wdrożenia, warto zatrzymać się przy tym, co agent faktycznie robi gdy odwiedza stronę.
Nie ma przeglądarki. Nie scrolluje. Nie klika w animacje. Nie widzi kolorów ani layoutu. Wysyła zapytanie HTTP, otrzymuje odpowiedź i przetwarza to co dostał.
Najpierw szuka pliku robots.txt — żeby wiedzieć, kto go wpuścił i co mu wolno. Potem szuka llms.txt — żeby dostać mapę serwisu zanim zacznie skanować podstrony. Potem przetwarza HTML strony głównej — sprawdza czy treść jest dostępna bez JavaScript, czy nagłówki tworzą logiczną hierarchię, czy dane strukturalne mówią mu kto i co. Jeśli tego nie znajdzie — skanuje na oślep. Dostaje to co dostaje.
To jest kluczowa różnica między optymalizacją pod Google a optymalizacją pod agentów. Google ma bota który indeksuje i rankuje. Agent ma zadanie i działa w imieniu użytkownika. Cel jest inny. Oczekiwania są inne. Dane które są wystarczające dla Googlebota mogą być zupełnie niewystarczające dla agenta który ma coś zrobić — zarekomendować, zarezerwować, odpowiedzieć na konkretne pytanie.
Warstwa 1 — czytelność
Fundament. Agent który nie może odczytać strony bez renderowania JavaScript nie skorzysta z żadnej kolejnej warstwy.
Co to znaczy w praktyce: treść musi być w HTML, nie budowana dynamicznie przez skrypty. Strony oparte na React, Vue czy Next.js z renderowaniem po stronie klienta mają tu największy problem — agent dostaje pusty div zamiast treści. WordPress z Divi jest pod tym względem bezpieczniejszy, bo treść trafia do HTML natywnie. Ale każdy element oparty na lazy load, każda sekcja ładowana po scrollu, każdy lightbox — warto sprawdzić.
Test jest prosty. Wyłącz JavaScript w przeglądarce i odśwież stronę. To co widzisz — widzi agent.
Drugi element czytelności to semantyczny HTML. Znaczniki <main>, <article>, <nav>, <header>, <footer> zamiast generycznych <div>. Hierarchia nagłówków — jeden <h1>, logiczne <h2> i <h3> jako spis treści. Atrybut alt na obrazach który coś znaczy, nie jest pustym stringiem.
Trzeci element — czas odpowiedzi serwera. W badaniu 165 stron, webflux.pl odpowiadał w 1398ms. bdaudyt.pl — 223ms. Agent który obsługuje wiele zapytań równolegle preferuje szybkie serwery. To nie jest element najważniejszy, ale jest mierzalny.
Stan w polskim rynku: HTTPS ma 100% stron w próbie. Semantyczny HTML — wyższy odsetek niż się spodziewałem, ale jakość nagłówków jest nierówna. Najczęstszy problem: strony gdzie designerskie decyzje („tu H2 wygląda lepiej niż H3″) niszczą hierarchię semantyczną.
Warstwa 2 — struktura danych
Schema.org i JSON-LD. Dane strukturalne które mówią agentowi co jest czym.
Co mierzę: obecność schema Organization z pełnymi danymi firmy, Person dla autora lub właściciela, FAQ schema dla sekcji z pytaniami i odpowiedziami, BreadcrumbList dla podstron, Open Graph dla mediów społecznościowych.
Stan w polskim rynku: 75% stron w próbie ma schema.org — to wynik lepszy niż się spodziewałem. Problem leży gdzie indziej: obecność schema.org to nie to samo co kompletność schema.org.
Agent który dostaje Organization z samą nazwą i URL-em dostaje schema.org. Ale agent który dostaje Organization z sameAs wskazującym na LinkedIn, KRS, profil Google Business, z contactPoint ze szczegółami kontaktu, z founderwskazującym na Person z numerem PIBR — dostaje coś całkowicie innego.
Różnica między tymi dwoma scenariuszami to różnica między „agent wie że istnieje firma o tej nazwie” a „agent wie kto za nią stoi, jak ją zweryfikować i jak się skontaktować”.
W badaniu warstwę struktury danych sprawdzam osobno dla Organization, Person, FAQ, BreadcrumbList i spójności między schema a treścią. Pełna spójność — czy cena w schema.org zgadza się z ceną widoczną na stronie — jest trudna do zautomatyzowania, więc ją szacuję. Ale znane są przypadki stron, gdzie schema podaje inną cenę niż HTML. Agent traktuje to jako sygnał braku wiarygodności.
Warstwa 3 — odkrywalność
robots.txt, llms.txt, Content Signals. To jest warstwa, w której polskie strony mają największe zaległości.
robots.txt: 88% stron w próbie ma robots.txt. To dobry wynik. Ale w ilu z nich są reguły specyficzne dla agentów AI — GPTBot, ClaudeBot, PerplexityBot, Google-Extended? W próbie z raportu: znacznie mniej. Domyślny robots.txt z Yoast albo RankMath nie zawiera tych reguł. To plik który był pisany dla wyszukiwarek, nie dla agentów.
Brak reguł dla AI crawlerów nie znaczy że strona jest zablokowana. Znaczy że strona nie ma świadomej polityki. Agent nie wie czy jest mile widziany czy tolerowany. Wie tylko że nikt nie pomyślał o nim przy konfiguracji.
llms.txt: 23% stron w próbie. To jest liczba, która mnie zaskoczyła — spodziewałem się mniej. Ale wśród stron które llms.txt mają dominują firmy technologiczne i SaaS. W e-commerce i agencjach digital — znacznie rzadziej. To jest plik który mówi agentowi czym jest serwis zanim zacznie go skanować. 324 słów opisu i lista kluczowych podstron — to wystarczy żeby agent wiedział gdzie jest i co znajdzie. Bez llms.txt skanuje na oślep.
Content Signals: 4 strony z 165. 2,4%. To jest deklaracja polityki treści — search=yes, ai-input=yes, ai-train=no jako linia w robots.txt. Standard Cloudflare z września 2025, z umocowaniem prawnym w Artykule 4 Dyrektywy UE 2019/790. Praktycznie nikt tego nie wdrożył. To jest najrzadszy element w całym badaniu.
Warstwa 4 — operacyjność
Czy agent może coś zrobić na stronie — nie tylko przeczytać.
Formularz kontaktowy bez CAPTCHA. API lub endpoint danych (WordPress REST API jest dostępny domyślnie, ale czy jest otwarty dla agentów?). Dane kontaktowe w maszynowo czytelnej formie — tel: i mailto: linki, ContactPoint schema.
W badaniu widzę dużo stron z formularzem za reCAPTCHA, który agent nie przejdzie. To jest celowy wybór — właściciel nie chce automatycznych wysyłek. Ale konsekwencja jest taka, że agent który ma zadanie „umów konsultację”może tylko pokazać użytkownikowi numer telefonu, nie może złożyć zapytania.
To nie jest błąd. To jest decyzja. Ale warto ją podjąć świadomie.
Warstwa 5 — tożsamość
Kto stoi za stroną? Czy agent może to zweryfikować?
W badaniu sprawdzam: Organization z sameAs, Person JSON-LD dla autora, NIP/KRS w stopce, politykę prywatności z linkiem. Tożsamość 10/10 w badaniu miała jedna strona — bdaudyt.pl, kancelaria biegłego rewidenta. Żadna strona z raportu nie osiągnęła kompletem w tym filarze.
Dlaczego tożsamość ma znaczenie w kontekście agentów AI? Bo modele językowe mają tendencję do preferowania źródeł o weryfikowalnej tożsamości przy cytowaniu i rekomendowaniu. Strona która mówi „jesteśmy ekspertami” i strona która mówi „oto numer PIBR naszego biegłego rewidenta, oto KRS, oto profil na LinkedIn, oto sameAs” — są przez agenta traktowane inaczej.
Warstwa 6 — governance
Świadoma polityka wobec agentów AI. Kogo wpuszczasz, co im wolno, czego zabraniasz.
Większość polskich stron ma governance przez domyślne ustawienia — czyli przez brak decyzji. Agent może crawlować bo robots.txt na to pozwala. Może pobierać treść do treningu bo nie ma Content Signals z ai-train=no. Może używać treści jako kontekstu dla odpowiedzi bo nie ma ai-input zadeklarowanego.
Brak deklaracji nie jest ani zgodą ani odmową. Jest brakiem polityki. W miarę jak standardy dojrzeją — brak polityki będzie coraz bardziej wyjątkiem, nie normą.
Co możesz wdrożyć dziś
Pięć kroków w kolejności trudności i wpływu.
Krok 1 — llms.txt. Piętnaście minut. Generator na iFox.pl, wgrywasz plik. Agent który trafi na Twoją stronę będzie wiedział czym jest firma i gdzie szukać kluczowych informacji.
Krok 2 — robots.txt z regułami AI. Dziesięć minut. Generator na iFox.pl, zastępujesz obecny robots.txt. Reguły dla 14 agentów AI, Content Signals, klauzula Cloudflare z Artykułem 4 UE.
Krok 3 — Schema Organization i Person. Trzydzieści minut. Generator na iFox.pl, wklejasz JSON-LD w WordPress przez RankMath lub Headers and Footers. Pełne dane firmy, dane autora, sameAs wskazujące na weryfikowalne zewnętrzne profile.
Krok 4 — FAQ schema. Jedna godzina. Jeśli masz sekcję FAQ na stronie — ustrukturyzuj ją w FAQPage schema. Agent który dostaje pytanie na które odpowiedź jest w Twojej FAQ może ją wyciągnąć bezpośrednio z danych strukturalnych.
Krok 5 — GEO Checker. Pięć sekund. Sprawdź gdzie jesteś. Wynik 0–100, sześć filarów, konkrety co jest do poprawienia. Nie zgaduj.
Co jest poza tą warstwą
Warstwa web jest wejściem. Ale agentic web to sześć warstw — i każda kolejna zakłada że poprzednia jest zrobiona.
Wpis 2 tej serii dotyczy warstwy commerce. Agenty zakupowe ChatGPT, Copilot Checkout, protokoły UCP i ACP. To jest warstwa która dla polskich sklepów internetowych staje się pilna właśnie teraz — bo Instant Checkout jest produkcyjny, a polskie sklepy mają średnio 43/100 w GEO Checkerze.
Warstwa web jest fundamentem. Bez niej reszta nie ma na czym stać.
Sprawdź wynik swojej strony: ifox.pl/geo-checker/
Generator llms.txt: ifox.pl/generator-llms/
Generator robots.txt z Content Signals: ifox.pl/generator-robots-txt/
Słownik pojęć tej serii: webflux.pl/slownik-agentic-web/
Raport AI-Readiness 2026: webflux.pl/raport-ai-readiness-2026/