Dwa dni temu opublikowałem raport o gotowości 165 polskich stron na agentów AI. Średni wynik: 47,5/100. Żadna strona nie osiągnęła progu AI-Ready.
Zaraz po publikacji uruchomiłem ten sam agent — ten sam kod w Go, ta sama metodologia — na webflux.pl i cyberflux.pl.
Nie po to, żeby sprawdzić własny wynik. Po to, żeby zobaczyć, co agent faktycznie widzi, gdy odwiedza stronę po wdrożeniu. I porównać to z tym, co widział przez poprzednie 165 wizyt.
To jest zapis tej obserwacji.
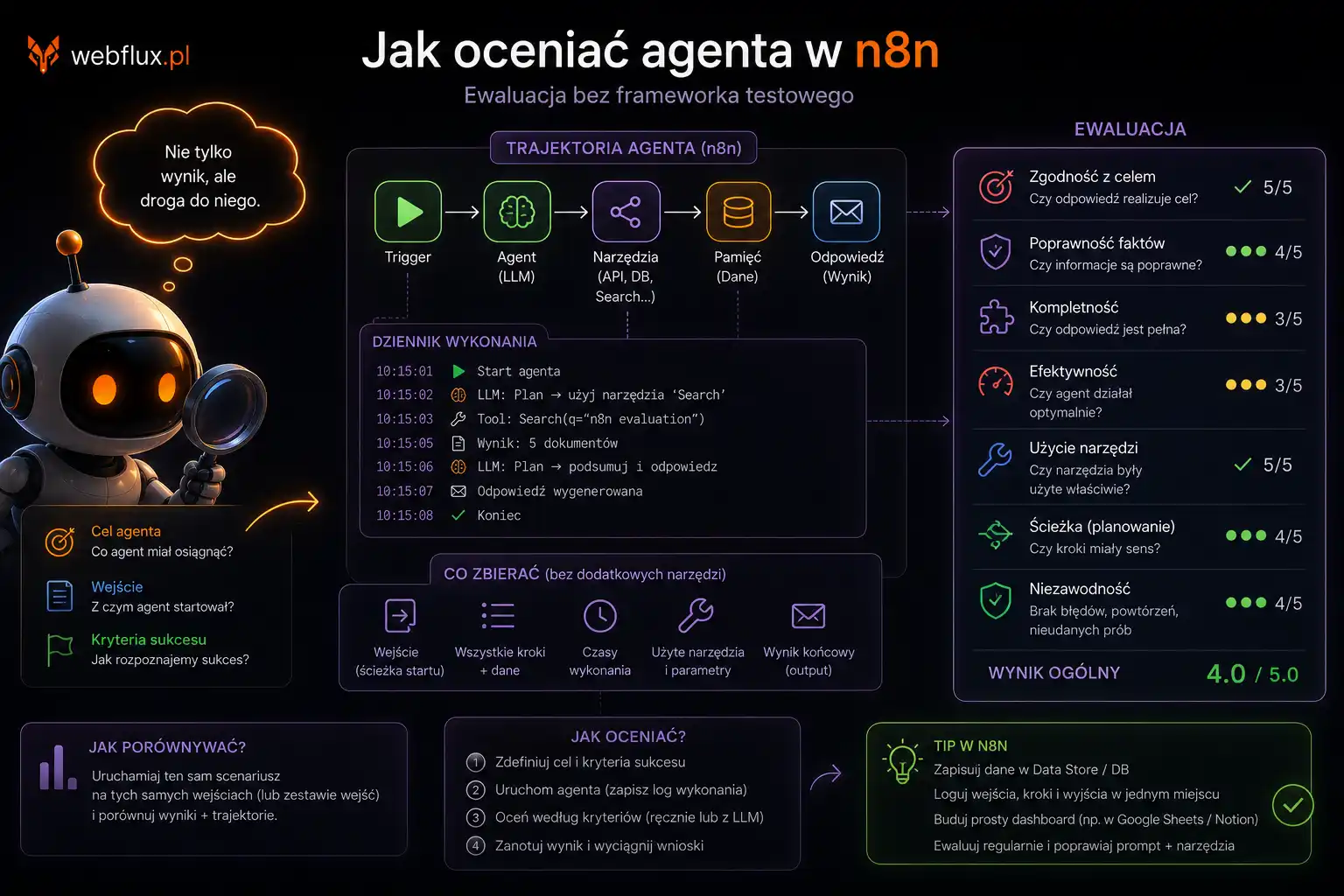
Co agent widzi na przeciętnej polskiej stronie
Z raportu wynika, że agent odwiedzający typową polską stronę branżową dostaje mniej więcej taki zestaw informacji:
Strona odpowiada przez HTTPS. Ma robots.txt — w 88% przypadków. W pliku robots.txt jest zazwyczaj Disallow: /wp-admin/ i nic więcej. Żadnych reguł dla GPTBot, ClaudeBot, PerplexityBot. Żadnych Content Signals. Agent wchodzi i nie wie, co mu wolno.
Strona ma schema.org — w 75% przypadków. Zazwyczaj to Organization z nazwą i adresem URL. Bez sameAs, bez danych kontaktowych, bez Person wskazującego na autora treści. Agent wie, że to jakaś organizacja. Nie wie, kto za nią stoi, jak ją zweryfikować, kto tu pisze.
Llms.txt nie ma — w 77% przypadków. Agent skanuje stronę na oślep. Nie wie, co tu znajdzie, które treści są ważne, jak jest zorganizowana nawigacja. Skanuje jak w ciemności.
Treść jest dostępna bez JavaScript — przeważnie tak, bo podstawowy HTML jest obecny. Ale strona nie mówi agentowi nic o tym, jak go traktuje. Klient, pasożyt czy złodziej — agent nie wie, w której kategorii jest.
To jest doświadczenie agenta na stronie z wynikiem 47,5/100. Nie złe. Nie wrogie. Po prostu — głuche.
Co agent zobaczył na webflux.pl
Wynik webflux.pl: 82/100.
Zacznę od tego, co agent zobaczył zanim przeczytał pierwszą linię treści.
robots.txt — są reguły dla konkretnych agentów AI. GPTBot, ClaudeBot, PerplexityBot, Google-Extended. Każdy dostaje jawną politykę dostępu. Agent wie, że ktoś świadomie zaprojektował ten plik pod agenty, nie tylko pod Googlebota.
Content Signals: 3/3 — search=yes, ai-input=yes, ai-train=yes. Trzy sygnały, wszystkie zadeklarowane. Agent nie musi zgadywać, co mu wolno. Właściciel strony powiedział wprost: możesz indeksować, możesz używać jako kontekstu, możesz trenować. To jest deklaracja polityki, nie milczenie.
llms.txt — 520 słów. Nie plik. Treść.
520 słów to nie jest dużo w ludzkiej skali — to jeden krótki artykuł. W skali agenta odwiedzającego stronę to różnica między mapą a kompasem. Agent który przeczytał llms.txt webflux.pl wie: czym jest serwis, jakie ma główne tematy, gdzie jest słownik, gdzie są narzędzia, jak dotrzeć do ekosystemu (iFox, CyberFlux, Studio), jak skontaktować się z autorem. Zanim odwiedził pierwszą podstronę.
/dla-agentów — obecne. Osobny endpoint z indeksem dla agentów. Agent wie, że ktoś przygotował dla niego osobne wejście.
422 słowa treści dostępne bez JavaScript. Strona główna dostarcza agentowi prawie pół tysiąca słów bez uruchamiania czegokolwiek. Agent nie musi renderować, nie musi klikać, nie musi czekać na async.
JSON-LD Person — agent wie, kto pisze. Nie anonimowy serwis. Autor z imieniem, z atrybucją, identyfikowalny. To ma znaczenie dla modeli, które ważą wiarygodność źródła.
BreadcrumbList — agent rozumie hierarchię nawigacji. Wie, w którym miejscu struktury jest każda strona, którą odwiedza.
MCP server — tego JSON nie mierzy bezpośrednio, ale agent który zna webflux.pl wie o istnieniu webflux.pl/wp-json/webflux/v1/mcp. Może odpytać 46 pojęć słownika w jednym zapytaniu. Może dostać definicję agent-readiness, llms.txt, Content Signals bez scrapowania osobnych podstron.
To jest różnica między stroną, która jest, a stroną, która odpowiada.
Co agent zobaczył na cyberflux.pl
Wynik cyberflux.pl: 70/100.
Niższy niż webflux.pl — z powodów, które omówię osobno. Ale jedno kryterium cyberflux.pl wygrywa zdecydowanie.
llms.txt — 1394 słów.
Prawie trzy razy więcej niż webflux.pl. Agent odwiedzający cyberflux.pl dostaje przed pierwszą wizytą na podstronie blisko półtorej tysiąca słów kontekstu o serwisie. Tematyka, struktura, najważniejsze wątki, kluczowe pojęcia z dziedziny bezpieczeństwa agentic web — wszystko w jednym pliku.
Dla agenta który ma odpowiedzieć na pytanie „co cyberflux.pl pisze o prompt injection?” — llms.txt z 1394 słowami to punkt startowy, który eliminuje ślepe uliczki. Agent nie musi skanować 60+ wpisów żeby zrozumieć strukturę serwisu. Dostaje mapę.
Content Signals: 3/3 — identycznie jak webflux.pl. Trzy sygnały, wszystkie zadeklarowane.
1835 słów treści bez JavaScript. To jest cztery razy więcej niż webflux.pl. Cyberflux jest serwisem z dużą ilością tekstu na stronie głównej — lista wpisów, opisy, nagłówki. Agent dostaje bogaty wgląd w zawartość bez renderowania.
/dla-agentów — obecne. Ten sam pattern co webflux.pl.
Organization z sameAs — agent może zweryfikować tożsamość serwisu przez zewnętrzne referencje.
Gdzie cyberflux.pl przegrywa z webflux.pl: brak Person JSON-LD, brak BreadcrumbList, brak reguł dla konkretnych AI user-agentów w robots.txt (jest User-agent: * z Content Signals — co jest poprawne, ale crawler nagradza explicite wymienione boty). To są luki do następnej iteracji.
Czego nie mierzy score
82/100 i 70/100 — to są liczby, które mówią, co istnieje. Nie mówią, co działa.
Llms.txt z 520 słowami na webflux.pl nie jest cenny dlatego, że plik istnieje. Jest cenny dlatego, że agent po jego przeczytaniu rozumie ekosystem — trzy projekty, ich role, główne tematy, sposoby kontaktu. Gdyby llms.txt miał 20 słów i jeden nagłówek — score byłby ten sam, doświadczenie agenta zupełnie inne.
Content Signals deklarujące search=yes, ai-input=yes, ai-train=yes — to jest świadoma decyzja. Webflux i CyberFlux zdecydowały na otwartą politykę wobec agentów. Inna strona mogłaby mieć Content Signals z ai-train=no i ai-input=no — score byłby identyczny, polityka odwrotna.
MCP server słownika — tego score w ogóle nie mierzy. A to jest element, który zmienia jakość odpowiedzi modeli AI pytanych o pojęcia agentic web po polsku. Agent z dostępem do MCP webflux.pl i agent bez tego dostępu — to są dwa różne agenty, nawet jeśli odwiedzają tę samą stronę.
Score mierzy, czy infrastruktura istnieje. Wartość jest w tym, co ta infrastruktura zawiera.
Co z tego wynika praktycznie
Różnica między webflux.pl a przeciętną polską stroną z raportu nie jest różnicą w score. Jest różnicą w tym, co agent może zrobić po wizycie.
Agent który odwiedził przeciętną polską stronę (47,5/100) wie: ta strona istnieje, prowadzi ją jakaś organizacja, ma robots.txt. Nie wie: czym się zajmuje szczegółowo, kto za nią stoi, co mu wolno, gdzie są najważniejsze treści, jak jest zbudowany ekosystem, jak dotrzeć do autora.
Agent który odwiedził webflux.pl wie: to jest serwis o agentic web po polsku, prowadzony przez Łukasza Jajora (Vereri), z ekosystemem trzech projektów (webflux = wiedza, iFox = narzędzia, CyberFlux = cybersec), ze słownikiem 46 pojęć dostępnym przez MCP, z narzędziami na ifox.pl, z możliwością kontaktu przez lukasz@vereri.pl. Wie, co mu wolno — bo zadeklarowaliśmy to wprost. Wie, gdzie szukać — bo llms.txt dało mu mapę.
To nie jest różnica w technicznych checkboxach. To jest różnica między agentem, który na pytanie użytkownika o agentic web po polsku może odpowiedzieć cytując webflux.pl — i takim, który może co najwyżej powiedzieć „jest strona która się tym zajmuje”.
Dla kogo to ma znaczenie dziś
Dla każdej firmy, której klienci używają ChatGPT, Perplexity, Claude albo asystentów AI na telefonach do szukania informacji, produktów i usług.
Agent działający w imieniu takiego klienta odwiedza strony. Czyta robots.txt. Szuka llms.txt. Sprawdza schema.org. Ocenia, ile może się dowiedzieć z jednej wizyty. Jeśli nie może się dowiedzieć wystarczająco dużo — przechodzi dalej.
Wdrożenie agent-readiness nie jest o score. Jest o tym, żeby agent który trafi na Twoją stronę — wiedział, co tu znajdzie, komu ufa i co może z tym zrobić.
Takie wdrożenia robimy już w Studio.iFox.pl. Robimy audyty tego co jest – zmiany mogą być wprowadzone ale nie uwzględniać wszystkich przypadków. Projektujemy i w prowadzamy zmiany – żeby jak najlepiej przedstawić Twój biznes odwiedzającemu agentowi. Weryfikujemy – nie tylko ogólnie dostępnymi narzędziami, ale puszczamy własnych agentów żeby przedstawili co znaleźli i jak strona widoczna była z ich perspektywy.
studio.ifox.pl — kontakt: lukasz@vereri.pl