W poprzednim wpisie koncepcyjnym pokazałem, że agenci na twojej stronie są albo klientami, albo pasożytami, albo złodziejami. Rozróżnienie jest koncepcyjnie proste, ale w praktyce nie da się go zrobić, dopóki nie wiesz kto dokładnie odwiedza twoją stronę. Polityka wobec agentów oparta na „wydaje mi się, że mam dużo ruchu od ChatGPT” jest polityką w ciemno. Filar szósty wymaga najpierw widzenia, potem decydowania.
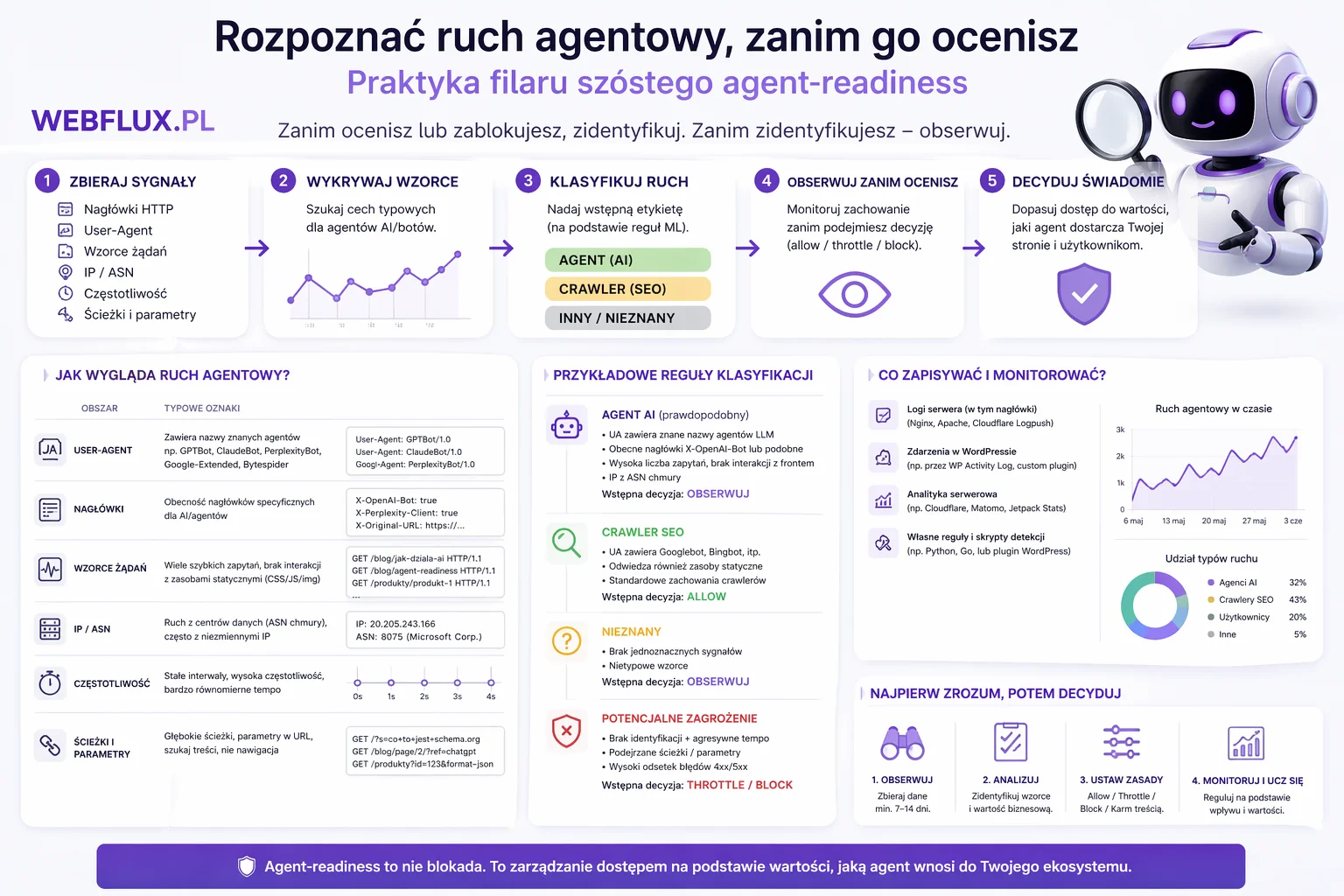
Ten wpis jest o widzeniu. Jak realnie, w konkretnych narzędziach, zobaczyć ruch agentowy na swojej stronie. Jak go posegmentować. Jak — po rozpoznaniu — ustawić politykę, która odpowiada temu co widzisz, a nie temu co sobie wyobrażasz. To jest najbardziej operacyjny wpis w całej serii Agent-ready. Mniej o filozofii, więcej o tym, gdzie kliknąć, jaki plik edytować, co zapisać w logach.
Jedna uwaga o kontekście, bo dziś jest to ważne. Do tej pory seria miała naprzemiennie wpisy koncepcyjne (w kategorii SEO i widoczność) i towarzyszące praktyczne (w kategorii Divi 5). Od tego wpisu zmieniam rytm — filar 6 i zamykający są w kategorii głównej, nie w Divi, bo dotyczą warstwy, w której builder strony nie gra głównej roli. Agent-readiness okazał się przy pisaniu czymś, co wykracza poza wybór buildera. WordPress jako podstawa, hosting i Cloudflare jako warstwa operatorska, wtyczki analityczne jako okno w to co się dzieje — to jest realna architektura, na której trzeba pracować.
Obszar pierwszy — jak zobaczyć ruch agentowy
Dopóki nie zbierzesz danych, twoja polityka wobec agentów jest abstrakcją. Z perspektywy marca-kwietnia 2026 większość polskich stron nie ma pojęcia ile agentów u nich jest, z jakich dostawców, jak się zachowują. Nie dlatego że brakuje narzędzi — dlatego że nikt nie włączył tej warstwy monitoringu. Zmiana tego to pierwsza praktyczna robota w filarze 6.
Trzy źródła danych, które pokrywają większość potrzeb.
Logi serwera WWW. Najbardziej surowe, najbardziej kompletne. Każdy hosting — od najmniejszego shared po profesjonalny VPS — zapisuje access logs, w których jest user-agent każdego żądania HTTP. Pokazywałem to w wpisie o filarze trzecim, ale teraz rozszerzamy zastosowanie. Zamiast tylko liczyć wejścia konkretnych botów, w filarze 6 chcesz wzorce: które strony odwiedza GPTBot, jak długo tam zostaje (jeśli pobiera wiele zasobów), jaki jest rozkład czasowy, czy wraca codziennie czy sporadycznie.
Praktycznie — pobierz plik access.log (zazwyczaj access.log.1.gz albo przez panel hostingu), wyciągnij linie dla interesujących cię user-agentów, zlicz i posegmentuj. Jeśli masz dostęp do linii komend:
# Liczba wejść per bot AI w ostatnim pliku logu
for bot in "GPTBot" "ChatGPT-User" "ClaudeBot" "Claude-User" "PerplexityBot" "Bytespider" "Amazonbot" "Meta-ExternalAgent"; do
count=$(grep -i "$bot" access.log | wc -l)
echo "$bot: $count"
done
# Top 10 najczęściej odwiedzanych stron przez GPTBot
grep -i "GPTBot" access.log | awk '{print $7}' | sort | uniq -c | sort -rn | head -10Jeśli nie masz linii komend, większość paneli hostingowych (cPanel, DirectAdmin) ma wbudowany parser logów (AWStats, Webalizer) z możliwością filtrowania po user-agent. Mniej elastyczne, ale wystarczające do wstępnego rozpoznania.
Panel Cloudflare. Jeśli twoja strona jest za Cloudflare, masz o klasę wygodniej. Od końca 2025 Cloudflare wypuścił dedykowaną sekcję AI Crawlers w panelu analitycznym. Znajdziesz tam rozbicie per dostawca (OpenAI, Anthropic, Google, Perplexity, Meta), trendy czasowe, obciążenie per bot, i — co najciekawsze — klasyfikację ruchu na „verified” (bot z potwierdzonego IP i zachowaniem zgodnym z deklaracją) vs „unverified” (deklaruje się jako konkretny bot, ale coś się nie zgadza).
Dokładna nawigacja różni się w zależności od wersji panelu, ale zasadnicza ścieżka to Analytics & Logs → Security lub Traffic → sekcja Bot analytics. Dla stron generujących znaczny ruch (powyżej 10 tysięcy wizyt miesięcznie) Cloudflare daje najczystszy obraz tego, co się dzieje — bo agreguje dane przed tym, jak dotrą do twojego serwera.
Wtyczki analityczne WordPress z rozpoznawaniem botów. Dla mniejszych stron, które nie są za Cloudflare i nie chcą grzebać w logach, jest trzecia droga. Wtyczki typu Wordfence (z sekcją Live Traffic), Burst Statistics, Matomo, Query Monitor — każda inaczej, ale wszystkie oferują jakąś formę identyfikacji ruchu botowego.
Wtyczki i narzędzia do monitoringu ruchu agentowego:
Wordfence Live Traffic — pokazuje w czasie rzeczywistym każde żądanie do strony, z user-agentem, IP, ścieżką. Główne zastosowanie to bezpieczeństwo, ale świetnie sprawdza się też jako podgląd ruchu botowego. Wymaga wersji Premium dla pełnej funkcjonalności w większym ruchu.
Burst Statistics — alternatywa dla Google Analytics, z prywatnościowym nastawieniem. Rozpoznaje popularne boty i pokazuje ich statystyki osobno od ruchu ludzkiego. Prostsza w użyciu od konfiguracji GA4 pod boty AI.
Matomo (dawniej Piwik) — pełne narzędzie analityczne z możliwością samodzielnego hostowania. Ma wbudowaną detekcję botów, którą da się rozszerzyć o własne definicje user-agentów.
Query Monitor — techniczna wtyczka do debugowania, ale pozwala zobaczyć surowe żądania trafiające do WordPressa, w tym ich user-agenty. Głównie dla developerów.
Cloudflare Analytics — jeśli masz stronę za Cloudflare, najpełniejszy obraz, bez instalacji wtyczki.
Rekomendacja praktyczna: jeśli masz Cloudflare, zacznij od niego — to najczystszy sygnał. Jeśli nie masz, zacznij od logów serwera i dorzuć jedną wtyczkę analityczną dla bieżącego podglądu. Nie instaluj trzech naraz — każda wtyczka kosztuje zasoby serwera, a dane z trzech źródeł rzadko są zgodne, co utrudnia analizę.
Obszar drugi — segmentacja, czyli kto jest kim
Kiedy już masz dane, zaczyna się prawdziwa praca filaru 6 — segmentacja. Bo listę user-agentów i liczbę wizyt trzeba zamienić w klasyfikację: które boty to klienci, które pasożyty, które potencjalni złodzieje (używam tej terminologii z wpisu #12 — jeśli zaczynasz od tego wpisu, wróć do klasyfikacji klient/pasożyt/złodziej po kontekst).
Praktyczna siatka segmentacji, którą możesz dziś zastosować do polskiej strony:
Boty trenujące modele (kandydaci na pasożyty). GPTBot od OpenAI, ClaudeBot od Anthropica, Google-Extended od Google, Bytespider od ByteDance, Meta-ExternalAgent od Mety, PerplexityBot od Perplexity. Te boty pobierają treść do trenowania modeli. Nie przynoszą bezpośredniego ruchu. W zależności od polityki ich dostawcy, mogą zapewnić późniejszą atrybucję (Claude czasem cytuje źródła, Perplexity to robi częściej), ale nie jest to gwarantowane. Dla większości treści to jest ruch, który konsumuje zasoby bez pewnej wzajemności.
Boty odpowiadające na żywo (kandydaci na klientów). ChatGPT-User od OpenAI, Claude-User od Anthropica, PerplexityBot jako on-demand (nie jako crawler treningowy — to ten sam user-agent w różnych trybach). Te boty odwiedzają twoją stronę w momencie, gdy konkretny użytkownik pyta o konkretną rzecz. Jeśli agent cytuje twoją stronę w odpowiedzi, istnieje szansa że użytkownik kliknie. Nawet jeśli nie kliknie — dostajesz atrybucję w odpowiedzi AI, co dla marki ma wartość.
Boty wyszukiwarek (klasyczne). Googlebot, Bingbot, YandexBot. Nie są agentami AI w węższym sensie, ale warto je monitorować w tym samym kontekście — zwłaszcza Googlebota, którego zachowanie w ostatnich kwartałach zaczyna zmieniać się pod kątem AI Overviews i Search Generative Experience.
Boty, których nie rozpoznajesz. Zawsze kilka procent ruchu to user-agenty spoza znanych list. Część to mniejsze firmy AI, które nie dbają o transparentność. Część to scrapery konkurencji albo agregatory. Część to user-agent spoofing (bot deklaruje się jako Chrome albo Firefox). Ta kategoria wymaga uwagi — jeśli nieznany user-agent generuje znaczny wolumen ruchu, warto sprawdzić co robi.
Dla każdego z tych segmentów pytanie brzmi: co ja z tego mam, co mnie to kosztuje. Pytanie praktyczne, nie moralne. Jeśli Bytespider generuje 30 tysięcy żądań miesięcznie, a ty nigdy nie widziałeś cytowania twojej strony w żadnym produkcie ByteDance — to jest prosta decyzja ekonomiczna. Jeśli ChatGPT-User generuje 5 tysięcy żądań, a ty widzisz konwersje z linków „via ChatGPT” w swoim analytics — to jest klient, którego warto wspierać.
Analiza per segment wymaga też uwagi na wzorce zachowania, nie tylko na liczby. Trzy pytania, które warto zadać każdemu segmentowi:
- Czy odwiedza konkretne strony, czy przechodzi przez wszystkie? Boty trenujące zazwyczaj próbują pobrać wszystko, agenci on-demand są selektywni.
- Czy respektuje robots.txt? Jeśli zablokowałeś bota w robots.txt, a on dalej odwiedza — to sygnał, że albo nie rozumie polityki, albo ją ignoruje.
- Czy deklarowany user-agent zgadza się z IP? Cloudflare to weryfikuje automatycznie. W logach serwera można sprawdzić reverse DNS — większość dużych operatorów publikuje listy IP dla swoich botów.
Obszar trzeci — polityki per segment
Segmentacja bez polityki jest intelektualną gimnastyką. Po rozpoznaniu kto jest kim, trzeba podjąć trzy rodzaje decyzji: komu dać pełny dostęp, komu ograniczony, kogo poprosić o rekompensatę.
Polityki dla kandydatów na klientów. ChatGPT-User, Claude-User, PerplexityBot w trybie on-demand. Zasada: pełny dostęp, ale z priorytetem dla ludzkich sesji w przypadku konfliktu zasobów. W praktyce:
- Nie blokuj w robots.txt (Allow: /)
- Jeśli masz rate limiting, ustaw wyższy limit dla tych botów niż dla nieznanych
- Jeśli masz ważne sygnały agent-readiness (JSON-LD, llms.txt), upewnij się że są one świetnie zrobione dla tych stron, które te boty prawdopodobnie odwiedzają
- Monitoruj czy te boty faktycznie odwiedzają — jeśli przez dwa miesiące nie zobaczyłeś wizyty ChatGPT-User, może twoja strona jeszcze nie jest w indeksie ChatGPT Search
Polityki dla kandydatów na pasożyty. GPTBot, ClaudeBot, Google-Extended, Bytespider w trybach treningowych. Tu są trzy dopuszczalne strategie, w zależności od profilu strony:
Strategia pełnego wpuszczenia. Pozwalasz trenować modele na swojej treści, w zamian za (niepewną) przyszłą widoczność w odpowiedziach AI. Sensowne dla stron, które zarabiają głównie na rozpoznawalności marki, nie na ruchu bezpośrednim.
Strategia pełnej blokady. Wpis w robots.txt: User-agent: GPTBot / Disallow: /. Rezygnujesz z treningu na twojej treści. Sensowne dla stron, które zarabiają na treściach eksperckich i nie chcą ich rozdawać modelom.
Strategia mixed. Najczęstsza w praktyce. Blokujesz boty treningowe, wpuszczasz on-demand. Różnicujesz politykę per sekcja strony — blog zablokowany dla treningu, opisy produktów dostępne dla wszystkich. Wymaga więcej pracy w konfiguracji, ale daje najlepszy kompromis.
Polityki dla potencjalnych złodziei. Boty, których nie rozpoznajesz, z wysokim wolumenem ruchu, z user-agent spoofingiem. Tu narzędzia są mocniejsze: WAF-y, rate limiting per IP/ASN, Cloudflare Bot Management w planach wyższych, wtyczki typu Blackhole for Bad Bots. Praktyka jest taka, że nie da się wyeliminować ich wszystkich — da się tylko podnieść koszt ich działania, żeby mniejsi atakujący się wycofali.
Pay-per-crawl — osobna warstwa dla wydawców. Cloudflare wypuścił w 2024 pay-per-crawl jako funkcję, która pozwala zażyczyć sobie mikropłatności od AI-crawlerów za każde pobranie treści. To nie jest standard branżowy, tylko funkcja konkretnego dostawcy, ale warto ją znać jako narzędzie. Mechanika: ustalasz cenę za pobranie zasobu, crawlery AI albo akceptują (płacą przez rozliczenie z Cloudflare) albo są zablokowane. W praktyce większość crawlerów dziś jeszcze nie obsługuje tej mechaniki — wielu po prostu odchodzi zamiast płacić. Ale kierunek jest ważny.
Dla kogo pay-per-crawl dziś ma sens? Głównie dla stron z dużą bazą treści o wysokiej wartości trening ingowej — dużych blogów eksperckich, serwisów informacyjnych, specjalistycznych portali. Dla mniejszych stron ekonomika na razie się nie domyka: przychód z pay-per-crawl jest niewielki, a ryzyko wypadnięcia z indeksu większych modeli AI realne. Ale to jest równanie, które za rok-dwa może wyglądać inaczej, więc warto monitorować tę warstwę.
Obok Cloudflare istnieją inne platformy agregujące ten model dla mniejszych wydawców — TollBit, ScalePost, czasem wewnętrzne programy konkretnych dostawców AI. Wszystko to jest rynek we wczesnej fazie, gdzie przez najbliższy rok prawdopodobnie część projektów zniknie, część się skonsoliduje, część dojrzeje. Jeśli prowadzisz stronę, dla której ta warstwa jest istotna — obserwuj, ale nie inwestuj pochopnie.
Co z tego wynika w sekwencji działań
Jeśli dziś masz stronę bez polityki wobec agentów i chcesz się tym zająć, oto kolejność, w której to działa najlepiej:
Po pierwsze — włącz widoczność. Ustaw monitoring ruchu agentowego. Cloudflare jeśli masz, wtyczkę analityczną jeśli nie. Przeanalizuj logi za ostatni miesiąc. Zapisz liczby dla każdego segmentu. Bez tego kroku każda kolejna decyzja jest w ciemno.
Po drugie — zdefiniuj politykę per segment. Napisz sobie (nawet jednym zdaniem) co robisz z GPTBot, co z ChatGPT-User, co z Bytespiderem, co z nieznanymi. Nie muszą to być skomplikowane reguły — ważne żeby były świadome.
Po trzecie — wdroż to w robots.txt, w Cloudflare, we wtyczkach. To jest najłatwiejsza część jeśli zrobiłeś pierwsze dwie. Konfiguracja jest szybka, gdy wiesz czego chcesz.
Po czwarte — monitoruj zmiany. Ruch agentowy w 2026 zmienia się z miesiąca na miesiąc. Nowi gracze, zmiany user-agentów, zmiany wolumenu. Wracaj do metryk raz w miesiącu. Decyzja, którą podjąłeś dziś, może nie pasować za pół roku.
Po piąte — rozważ warstwy zaawansowane. Pay-per-crawl, licencjonowanie przez platformy pośredniczące, specjalne umowy z dostawcami AI. To są kroki dla stron, które już zrobiły podstawową robotę i chcą eksperymentować z monetyzacją. Nie dla każdego — i nie od razu.
Agent-readiness: Praktyka filaru 6
Co dalej
Wpis zamykający serię pokaże pełną mapę sześciu filarów razem — priorytety wdrożenia, realistyczny harmonogram, od czego zacząć w zależności od profilu strony. Tam zamkniemy całość, w tym też decyzje które z filarów są najtańsze w implementacji, a które wymagają największego nakładu. Będzie też rozdział dla tych, którzy nie zrobili nic i nie wiedzą gdzie stanąć.
Jeśli o czymś z tego wpisu pamiętasz tylko jedno zdanie, niech to będzie: dane o ruchu agentowym to fundament filaru 6 i żaden proxy go nie zastąpi. Polityka oparta na wyobrażeniach jest polityką w ciemno. Cloudflare, logi serwera, wtyczka analityczna — to są narzędzia, które dziś, w 2026, dają ci możliwość zobaczenia tego, co naprawdę się dzieje. Bez tego cały filar 6 jest ćwiczeniem intelektualnym.
W hubie Universal Commerce Protocol rozpisuję protokolarną stronę tego filaru — UCP, AP2, mechanizmy rozliczania transakcji w agentic commerce. To jest widok z poziomu standardów, które powstają jako dłuższoterminowa odpowiedź na dzisiejszy chaos narzędzi. Warto łączyć jedno z drugim: dziś praca na narzędziach operatorskich, jutro — na standardach, kiedy się ustabilizują.