Po publikacji Polskiego Raportu AI-Readiness 2026 puściłem tego samego agenta na bdaudyt.pl — stronę firmy audytorskiej z Wrocławia, prowadzonej przez biegłego rewidenta Beatę Wachowicz.
Nie jest to klient Studio.iFox. Nie przebudowywałem tej strony. Nie wdrażałem na niej llms.txt ani robots.txt. Mogłem wskazać tematy, które warto sprawdzić — budowanie zrobiła właścicielka, samodzielnie, z własnej inicjatywy.
To jest zapis tego, co agent na tej stronie znalazł.
Kontekst, który ma znaczenie
W raporcie zbadałem 165 polskich stron branżowych. Żadna nie osiągnęła progu AI-Ready (85 punktów). Dwie osiągnęły kategorię Zaawansowana — synerise.com i ifirma.pl, obie z wynikiem 72/100.
bdaudyt.pl to firma audytorska. Kameralna praktyka z dwoma biurami — Wrocław i Ząbkowice Śląskie. Beata Wachowicz, biegły rewident numer 12851, ponad piętnaście lat doświadczenia. Jeden Partner, bezpośredni kontakt, bez warstw pośrednich.
Nie jest to firma technologiczna. Nie ma działu IT. Nie jest to startup SaaS który ma kulturę techniczną wbudowaną w DNA organizacji. To jest kancelaria finansowa — typ firmy, który w raporcie reprezentowały agencje digital, wypadające z wynikiem 47,1/100.
Wynik agenta: 83/100.
Przy czym — jak zaraz wyjaśnię — jest to wynik zaniżony przez wykryty już błąd w metodologii crawlera.
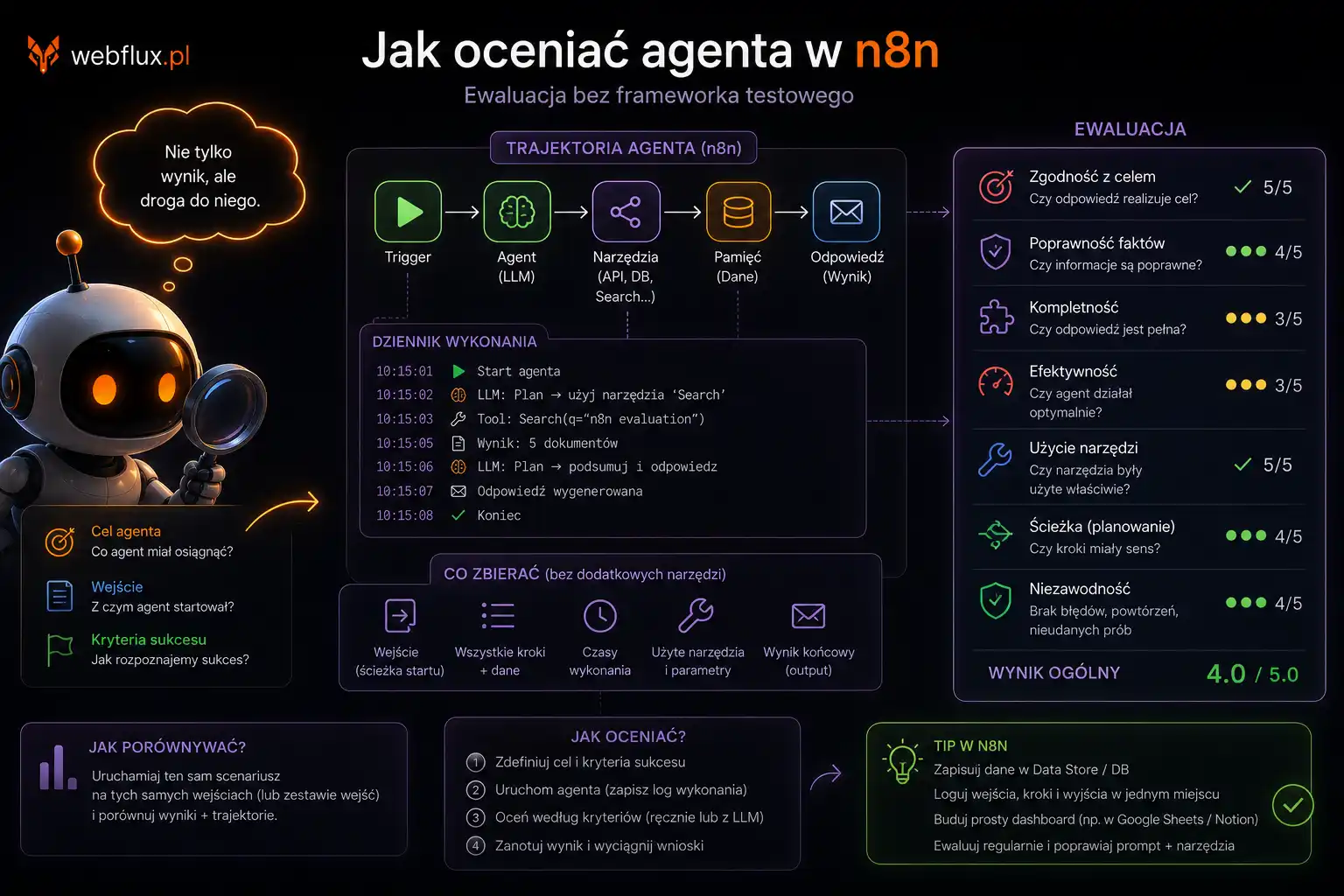
Co agent zobaczył — filar po filarze
Czytelność: 19/20
1456 słów treści dostępnej bez renderowania JavaScript.
To jest wynik, który pokazuje architekturę decyzji. Strona bdaudyt.pl nie jest zbudowana na WordPressie z dziesiątkami wtyczek i asynchronicznym ładowaniem treści. Jest lekka, szybka, statyczna w najlepszym znaczeniu tego słowa.
Agent odczytał ją bez uruchamiania czegokolwiek. Dostał pełny tekst — opis usług, profil biegłego rewidenta, FAQ z konkretnymi progami prawnymi badania, dane kontaktowe, politykę prywatności. Wszystko.
Czas odpowiedzi: 223 milisekundy.
Dla porównania: webflux.pl — 1398ms. cyberflux.pl — 1027ms. bdaudyt.pl odpowiada sześć razy szybciej niż webflux.pl. Nie jest to kwestia lepszego serwera — to kwestia tego, że strona nie ładuje tego, co ładować nie musi.
5/5 tagów semantycznych HTML5. Komplet. <main>, <article>, <nav>, <header>, <footer> — wszystko na miejscu. Agent nie musi zgadywać, gdzie jest nawigacja, a gdzie treść.
Jeden punkt stracony: redirect HTTP → HTTPS nie został potwierdzony przez crawler. Technicznie drobiazg, ale crawler go odnotował.
Struktura danych: 23/25
To jest filar, który odróżnia stronę budowaną z myślą o agentach od strony zoptymalizowanej pod SEO.
JSON-LD Person — agent wie, kto jest za stroną. Nie „firma audytorska”. Beata Wachowicz, biegły rewident numer 12851, z konkretnymi danymi.
Organization z sameAs — agent może zweryfikować tożsamość przez zewnętrzne referencje. Nie tylko nazwa i URL — zewnętrzny punkt potwierdzenia.
BreadcrumbList — agent rozumie hierarchię nawigacji.
FAQ/HowTo schema — to jest element, którego nie ma webflux.pl, cyberflux.pl, ani żadna z 165 stron z raportu. Sekcja FAQ na bdaudyt.pl nie jest tylko tekstem. Jest ustrukturyzowanymi pytaniami i odpowiedziami w formacie, który model językowy może odczytać jako FAQ — z pytaniem i odpowiedzią jako oddzielnymi, semantycznie zidentyfikowanymi elementami.
Agent który dostaje pytanie „kiedy spółka z o.o. musi mieć audyt?” — może odczytać odpowiedź bezpośrednio ze structured data, bez parsowania swobodnego tekstu. Progi: suma aktywów ≥ 2 500 000 EUR, przychody ≥ 5 000 000 EUR, zatrudnienie ≥ 50 osób — co najmniej dwa z trzech. Z kursu NBP z 31 grudnia 2025 r.
To jest odpowiedź, którą agent może przesłać użytkownikowi z pełną pewnością co do źródła.
Dwa punkty stracone na spójności schema — crawl nie weryfikuje spójności między danymi w JSON-LD a treścią widoczną, więc to jest algorytmiczne ograniczenie metody, nie realny problem.
Tożsamość: 10/10
Jedyna strona w całym teście — 165 stron z raportu plus webflux.pl i cyberflux.pl — która ma komplet w tym filarze.
Organization z sameAs — tak. Person JSON-LD — tak. Polityka prywatności — tak, z pełnym opisem podstaw prawnych przetwarzania danych, okresów retencji, odbiorców. NIP/KRS w stopce — tak. NIP: 8993055469, KRS: 0001232241, REGON: 544373582, kapitał zakładowy: 5 000 zł.
Agent który odwiedza bdaudyt.pl i chce zweryfikować, czy to realna firma z realnym biegłym rewidentem — może to zrobić bez opuszczania strony. Numer PIBR 12851 jest obecny, dane rejestrowe są kompletne, sameAs prowadzi do zewnętrznych potwierdzeń.
webflux.pl ma w tym filarze 4/10. Przeciętna polska strona z raportu — około 4 punktów. bdaudyt.pl ma 10.
Odkrywalność: 14/20
Tu jest luka — i tu jest też błąd crawlera, który wymaga nazwania.
robots.txt — dostępny, z regułami dla 10 agentów AI. Dla porównania: webflux.pl ma reguły dla 4 agentów, przeciętna polska strona z raportu — zero. Na liście: GPTBot, ClaudeBot, PerplexityBot, Google-Extended, Amazonbot, Applebot-Extended, meta-externalagent, CCBot, Bytespider, OAI-SearchBot — każdy z jawną deklaracją polityki dostępu.
llms.txt — dostępny, 324 słowa. Agent przed pierwszą wizytą na podstronie wie, z czym ma do czynienia: firma audytorska z Wrocławia, pięć obszarów praktyki, dane kontaktowe, jak umówić bezpłatną konsultację.
Crawler zgłasza Content Signals: 0. Tu jest błąd — i nie jest to błąd strony.
Znamy ten problem z cyberflux.pl. Crawler wykrywa Content Signals przez obecność osobnych wpisów User-agent: GPTBotz dyrektywą Content-Signal:. Gdy Content Signals są zadeklarowane w bloku User-agent: * — crawler ich nie widzi. To jest znany błąd w metodologii, który zostanie poprawiony w następnej edycji.
Beata Wachowicz ma Content Signals w robots.txt. Crawler tego nie widzi. Wynik jest zaniżony o 4 punkty w Odkrywalności i 3 punkty w Governance.
Brak /dla-agentów według crawlera — ale to jest kolejny błąd metodologii, nie luka strony. bdaudyt.pl ma ustawiony link rel="service-doc" w nagłówku HTTP odpowiedzi, wskazujący na llms.txt. Jest to równie poprawna implementacja jak osobna strona /dla-agentów — ale crawler szuka tego atrybutu wyłącznie w treści HTML, nie w nagłówkach HTTP. Kolejna znana luka do poprawki w następnej edycji.
Governance: 7/10
10 agentów AI wymienionych w robots.txt — pełne 4/4. robots.txt zaktualizowany pod AI — 3/3.
Content Signals: 0/3 według crawlera, faktycznie 3/3 według właścicielki. Znany błąd metodologii.
Wynik po korekcie
Crawler daje 83/100. Po uwzględnieniu trzech znanych błędów metodologii:
- Content Signals (odkrywalność): +4 → 18/20
- Content Signals (governance): +3 → 10/10
- service-doc w HTTP header: +2 → 16/20 odkrywalność
Łącznie: 92/100
92/100 to głęboko w kategorii AI-Ready. Próg: 85.
bdaudyt.pl jest pierwszą stroną w całym teście — 165 stron z raportu plus trzy własne — która przekracza ten próg. I to o siedem punktów.
Co agent może zrobić po wizycie na bdaudyt.pl
To jest pytanie, które score nie odpowiada wprost.
Agent który ma pomóc użytkownikowi znaleźć biegłego rewidenta do badania sprawozdania spółki z o.o. w Polsce:
- Wie, że bdaudyt.pl to firma audytorska we Wrocławiu prowadzona przez biegłego rewidenta nr 12851
- Wie, jakie są progi obowiązku badania dla 2026 roku — z konkretnymi liczbami w euro i złotówkach
- Wie, jak wygląda proces — 4 do 10 tygodni od podpisania umowy, większość pracy zdalnie
- Wie, że jest opcja bezpłatnej pierwszej rozmowy do 60 minut
- Może zweryfikować tożsamość przez NIP, KRS, numer PIBR
- Ma trzy numery telefonu i adres e-mail w formie maszynowo dostępnej
- Wie, co napisać w wiadomości żeby dostać szybką odpowiedź — forma prawna, przybliżone przychody, powód kontaktu
To jest komplet informacji potrzebnych do rekomendacji. Agent nie musi zgadywać, nie musi parsować chaotycznego tekstu, nie musi wnioskować z kontekstu. Ma dane.
Dla porównania — agent który trafia na przeciętną kancelarię finansową z raportu (47,5/100) dostaje: nazwę firmy, numer telefonu, ogólny opis usług. Musi zgadywać, czy to firma która robi audyt ustawowy, czy tylko doradztwo podatkowe. Musi szukać NIP w innym miejscu. Nie wie, kto prowadzi sprawę.
Różnica nie jest w score. Jest w tym, co agent może zrobić z informacjami.
Co z tego wynika
Trzy obserwacje.
Pierwsza. AI-Ready nie jest domeną firm technologicznych. bdaudyt.pl nie ma działu IT. Nie jest SaaSem. Jest kancelarią finansową z Wrocławia. Osiągnęła wynik, którego nie osiągnął żaden z 165 badanych serwisów — przez zrozumienie, co agent potrzebuje, nie przez duży budżet.
Druga. Metodologia crawlera ma dwa znane błędy w przypadku bdaudyt.pl. Pierwszy: detekcja Content Signals przez User-agent: * bez osobnych wpisów per bot. Drugi: detekcja rel="service-doc" wyłącznie w HTML, nie w nagłówkach HTTP. Oba zostaną poprawione w następnej edycji. Łączny wpływ na wynik bdaudyt.pl: -9 punktów. Z poprawkami: 92/100 zamiast 83/100.
Trzecia. human.txt. Na bdaudyt.pl jest plik, którego nasza metodologia nie mierzy. human.txt — analogon robots.txt, ale adresowany do ludzi odwiedzających stronę przez crawlery. Sygnał, że właścicielka myśli o dostępności na wielu warstwach jednocześnie. Nie mierzymy tego kryterium. Być może powinniśmy.
Sprawdź wynik swojej domeny: ifox.pl
Metodologia raportu: webflux.pl/raport-ai-readiness-2026/metodologia/
Wdrożenia agent-readiness: studio.ifox.pl — kontakt: lukasz@vereri.pl