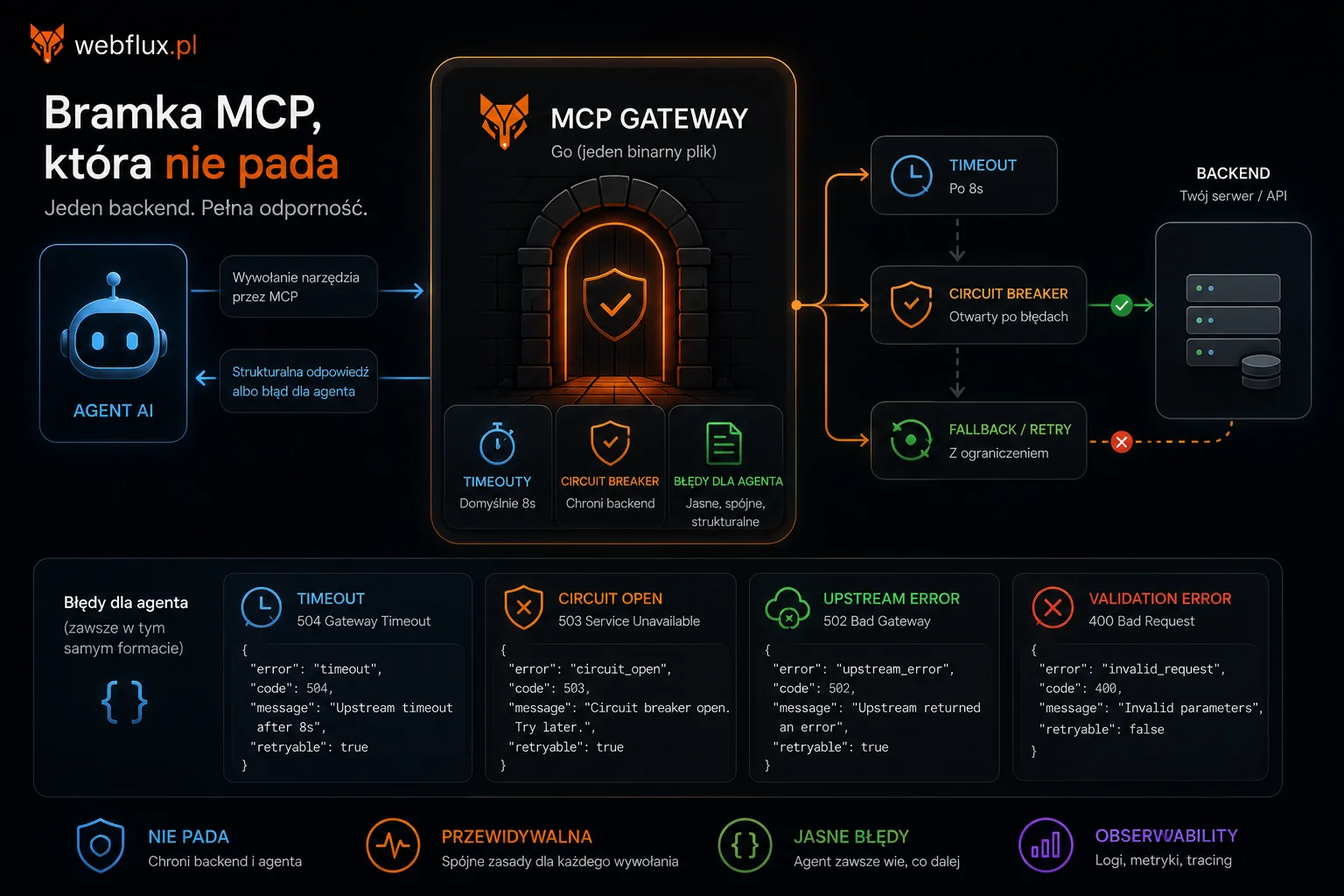
Przez dwadzieścia lat optymalizowaliśmy strony pod jeden model: robot wchodzi, czyta HTML, indeksuje, wychodzi. Robiliśmy to dobrze. Nauczyliśmy się semantycznego HTML, szybkiego ładowania, sitemap, structured data. Strona widoczna dla Google to dziś standard, nie przewaga.
Problem w tym, że agent AI nie jest Googlebottem. I zachowuje się zupełnie inaczej.

Co robi Googlebot
Googlebot to pająk. Wchodzi na stronę, pobiera HTML, parsuje tekst i linki, zapisuje co znalazł, wychodzi. Wraca za kilka tygodni.
JavaScript wykonuje — ale z opóźnieniem i selektywnie. Treść wstrzyknięta przez JS może nie zostać zindeksowana wcale albo z tygodniowym poślizgiem. Formularzy nie wypełnia. Przycisków nie klika. Nie scrolluje, żeby załadować lazy content. Nie wchodzi za bramkę logowania.
Crawler-ready to odpowiedź na te ograniczenia: tekst w HTML a nie w JS, linki jako prawdziwe <a href>, treść dostępna bez interakcji, szybki czas odpowiedzi serwera.
Co robi Claude in Chrome
Claude in Chrome to agent z przeglądarką. Dosłownie.
Otwiera Chrome, wchodzi na adres, widzi wyrenderowaną stronę — taką jak widzisz ją Ty. Wykonuje JavaScript. Klika przyciski. Scrolluje. Wypełnia formularze. Wchodzi do zakładek. Pobiera pliki. Wchodzi do iframe. Może otworzyć nową kartę, wrócić, porównać.
Nie czyta kodu źródłowego. Czyta stronę tak jak ją widzi człowiek — i na tej podstawie podejmuje decyzje.
To nie jest crawlowanie. To jest używanie strony.
Gdzie się rozjeżdżają
Weźmy konkretny przykład z eksperymentu który opisałem w poprzednim wpisie.
Salon kosmetyczny. Strona ma 10 instrukcji pielęgnacji do pobrania. Lista renderowana przez JavaScript, przyciski jako onclick, pliki pod nazwami dokument_01.pdf przez dokument_10.pdf.
Googlebot: nie widzi listy (JS), nie widzi plików (brak <a href>), nie indeksuje nazw zabiegów przy plikach. Z punktu widzenia crawlera ta sekcja nie istnieje.
Claude in Chrome: widzi wyrenderowaną listę, czyta etykiety na kartach („Laminacja brwi”, „Henna brwi”), klika przyciski, pobiera pliki. Radzi sobie bez problemu.
Ta sama strona. Dwa zupełnie różne wyniki.
I teraz odwrotnie. Strona z idealnym semantycznym HTML, opisowymi nagłówkami, pełnym tekstem w <article>, schema.org dla każdego zabiegu. Googlebot ją uwielbia. Ale — wszystkie linki do pobrania schowane za formularzem „podaj swoje imię i datę wizyty”. Agent musi zrozumieć kontekst formularza, wypełnić go, poczekać na odpowiedź, pobrać właściwy plik. Dziesięć razy.
Świetna dla crawlera. Trudna dla agenta.
Dlaczego to ważne teraz
Jeszcze rok temu jedynym robotem który regularnie odwiedzał Twoją stronę był crawler wyszukiwarki. Dziś dochodzi nowa klasa ruchu: agenty działające w imieniu użytkowników.
Klientka wysyła agenta żeby zebrał cenniki z pięciu salonów w okolicy. Agent wchodzi na każdą stronę i próbuje wykonać zadanie. Na stronach gdzie mu się to uda — klientka dostaje informacje, może porównać, może zadzwonić. Na stronach gdzie się nie uda — salon po prostu wypada z zestawienia. Nie dlatego że jest gorszy. Dlatego że agent nie dał rady.
Tego nie widać w Google Analytics. Nie ma w raporcie pozycji w wyszukiwarce. Jest tylko brak klienta, którego agent obsłużył gdzie indziej.
Trzy różnice które mają znaczenie
Interakcja. Googlebot nie klika. Agent klika. Jeśli cokolwiek na Twojej stronie wymaga interakcji przed ujawnieniem treści — dla crawlera to niewidoczne, dla agenta to zadanie do wykonania (albo bariera nie do przejścia).
Stan. Googlebot widzi stronę w jednym stanie — tym przy wejściu. Agent widzi stronę jako sekwencję stanów: wejście, kliknięcie zakładki, wypełnienie pola, zmiana widoku. Jeśli kluczowa treść jest w stanie który wymaga kilku kroków — crawler jej nie znajdzie, agent może.
Kontekst zadania. Googlebot indeksuje. Agent wykonuje zadanie. Te dwie czynności wymagają innych rzeczy od strony. Crawler potrzebuje tekstu i struktury. Agent potrzebuje żeby strona komunikowała co można na niej zrobić i jak — i żeby to działało bez zaskakiwania.
Co to znaczy praktycznie
Crawler-ready i agent-ready to nie są sprzeczności. Duża część dobrej praktyki SEO pomaga też agentom: semantyczny HTML, opisowe nagłówki, tekst zamiast obrazków z tekstem, szybkie ładowanie.
Ale są obszary gdzie ścieżki się rozchodzą:
Treść ładowana przez JS — niewidoczna dla crawlera, widoczna dla agenta. Formularz przed dostępem do treści — bariera dla crawlera i agenta, ale z różnych powodów i z różnymi konsekwencjami. Iframe — crawler go ignoruje, agent wchodzi do środka. Onclick bez href — crawler nie widzi akcji, agent może kliknąć jeśli widzi etykietę.
I jedno czego nie załatwia ani crawler-ready ani agent-ready samo w sobie: strona musi informować co można na niej zrobić. Jeśli masz 10 plików do pobrania ale nigdzie nie ma nagłówka „Instrukcje do pobrania” ani żadnego kontekstu — agent nie będzie ich szukał. Nie dlatego że nie potrafi. Dlatego że strona nie powiedziała mu że tam są.

Twoja strona jest widoczna dla Google. Dla agenta AI — niekoniecznie. Dlaczego to nie jest to samo.
Jeden wniosek
SEO nauczyło nas myśleć o stronie jako o dokumencie który ma być znaleziony. Agent-readiness każe myśleć o stronie jako o interfejsie który ma być użyty.
To jest zmiana perspektywy, nie checklista do odhaczenia. I zaczyna się od pytania: gdyby ktoś wysłał agenta żeby wykonał zadanie na mojej stronie — co by się stało?
Jeśli nie znasz odpowiedzi — warto sprawdzić.
Nie pytaj tylko, czy Google widzi Twoją stronę.
Sprawdź, czy agent potrafi wykonać na niej zadanie.